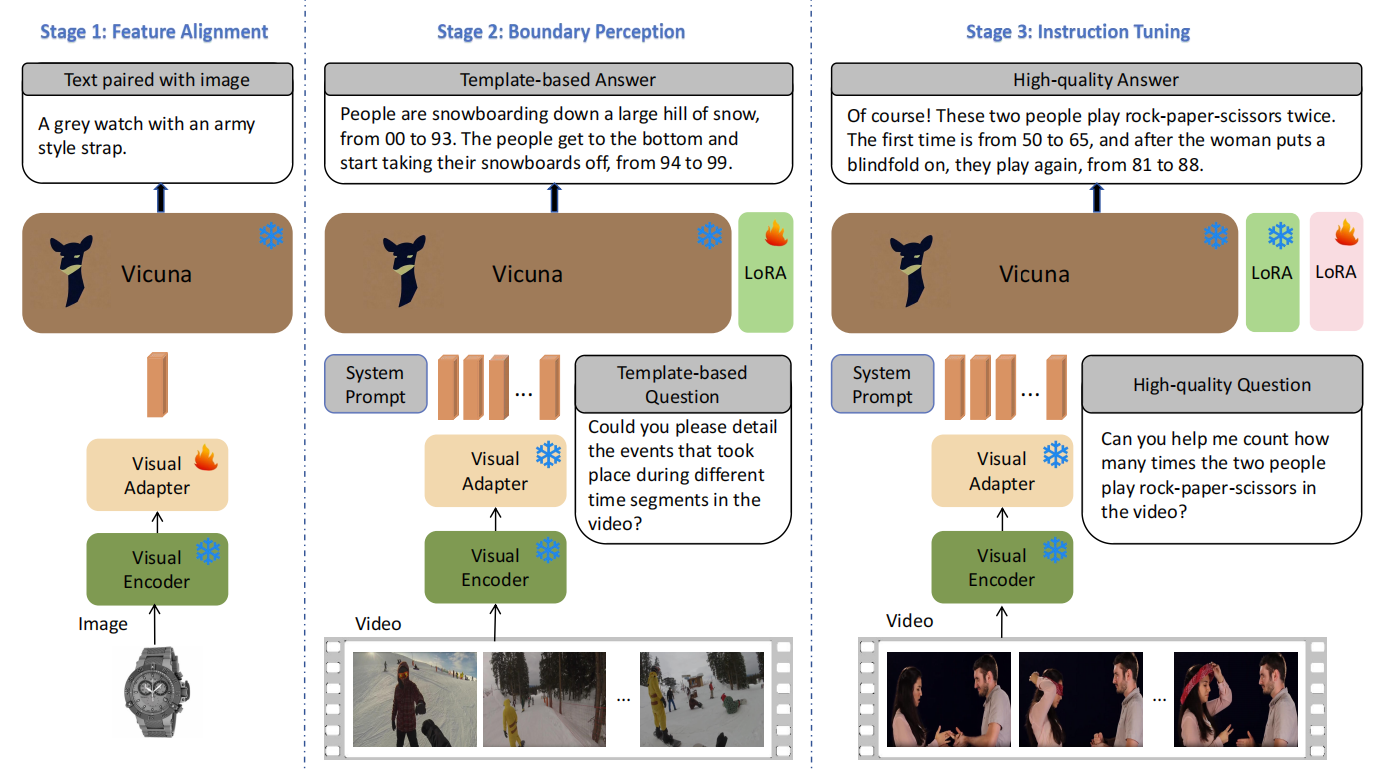
VTimeLLM: Empower LLM to Grasp Video Moments
Large language models (LLMs) have shown remarkable text understanding capabilities, which have been extended as Video LLMs to handle video data for comprehending visual details. However, existing Video LLMs can only provide a coarse description of the entire video, failing to capture the precise start and end time boundary of specific events. In this paper, we solve this issue via proposing VTimeLLM, a novel Video LLM designed for fine-grained video moment understanding and reasoning with respect to time boundary. Specifically, our VTimeLLM adopts a boundary-aware three-stage training strategy, which respectively utilizes image-text pairs for feature alignment, multiple-event videos to increase temporal-boundary awareness, and high-quality video-instruction tuning to further improve temporal understanding ability as well as align with human intents. Extensive experiments demonstrate that in fine-grained time-related comprehension tasks for videos such as Temporal Video Grounding and Dense Video Captioning, VTimeLLM significantly outperforms existing Video LLMs. Besides, benefits from the fine-grained temporal understanding of the videos further enable VTimeLLM to beat existing Video LLMs in video dialogue benchmark, showing its superior cross-modal understanding and reasoning abilities.
PDF AbstractCode

Tasks
 Dense Video Captioning
Video-based Generative Performance Benchmarking
Video-based Generative Performance Benchmarking (Consistency)
Video-based Generative Performance Benchmarking (Contextual Understanding)
Video-based Generative Performance Benchmarking (Correctness of Information)
Video-based Generative Performance Benchmarking (Detail Orientation))
Video-based Generative Performance Benchmarking (Temporal Understanding)
Video Captioning
Video Grounding
Dense Video Captioning
Video-based Generative Performance Benchmarking
Video-based Generative Performance Benchmarking (Consistency)
Video-based Generative Performance Benchmarking (Contextual Understanding)
Video-based Generative Performance Benchmarking (Correctness of Information)
Video-based Generative Performance Benchmarking (Detail Orientation))
Video-based Generative Performance Benchmarking (Temporal Understanding)
Video Captioning
Video Grounding
 ActivityNet Captions
ActivityNet Captions
 Charades-STA
Charades-STA
 DiDeMo
DiDeMo
 WebVid
WebVid

