VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers
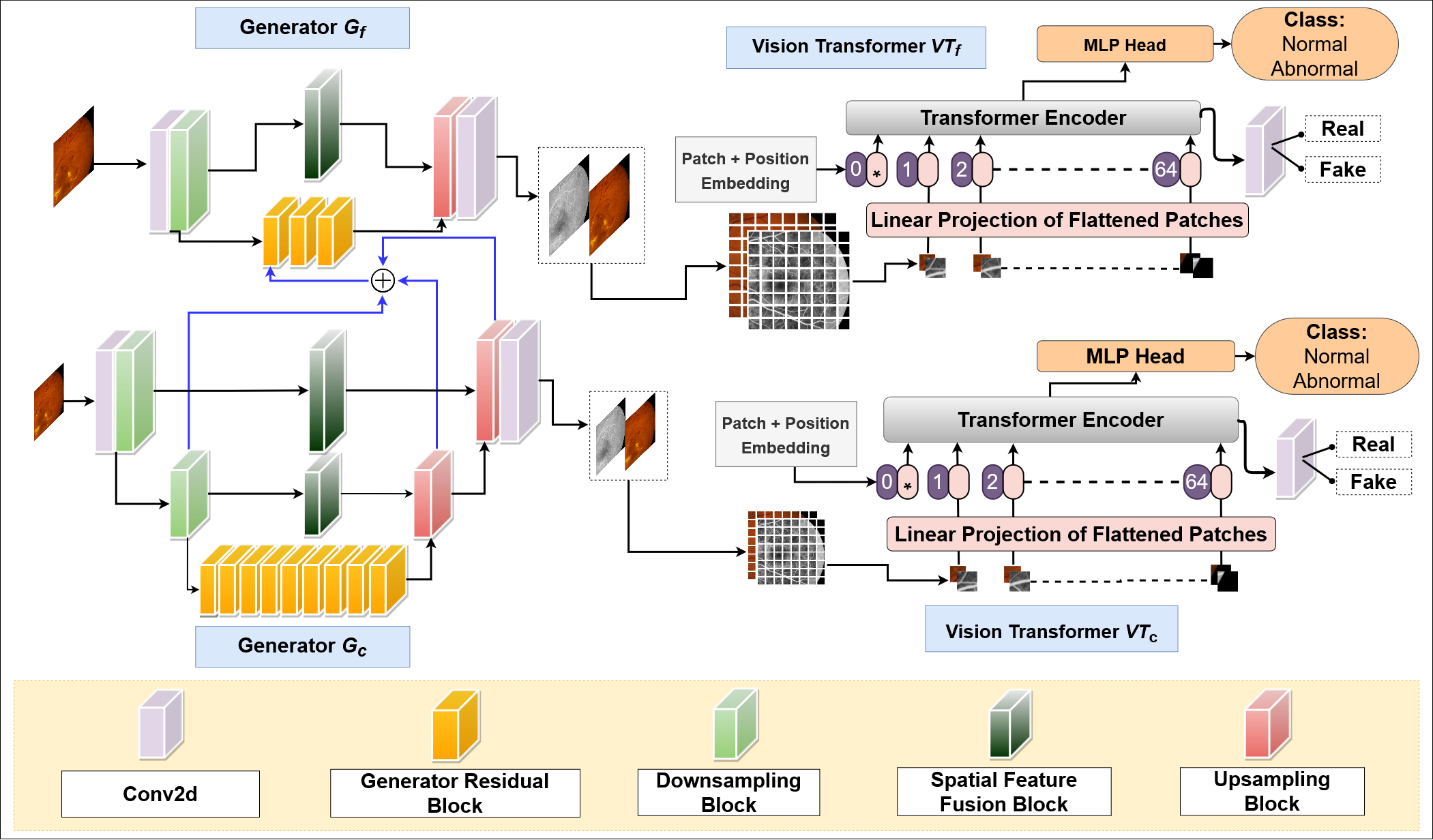
In Fluorescein Angiography (FA), an exogenous dye is injected in the bloodstream to image the vascular structure of the retina. The injected dye can cause adverse reactions such as nausea, vomiting, anaphylactic shock, and even death. In contrast, color fundus imaging is a non-invasive technique used for photographing the retina but does not have sufficient fidelity for capturing its vascular structure. The only non-invasive method for capturing retinal vasculature is optical coherence tomography-angiography (OCTA). However, OCTA equipment is quite expensive, and stable imaging is limited to small areas on the retina. In this paper, we propose a novel conditional generative adversarial network (GAN) capable of simultaneously synthesizing FA images from fundus photographs while predicting retinal degeneration. The proposed system has the benefit of addressing the problem of imaging retinal vasculature in a non-invasive manner as well as predicting the existence of retinal abnormalities. We use a semi-supervised approach to train our GAN using multiple weighted losses on different modalities of data. Our experiments validate that the proposed architecture exceeds recent state-of-the-art generative networks for fundus-to-angiography synthesis. Moreover, our vision transformer-based discriminators generalize quite well on out-of-distribution data sets for retinal disease prediction.
PDF Abstract





