VSFormer: Visual-Spatial Fusion Transformer for Correspondence Pruning
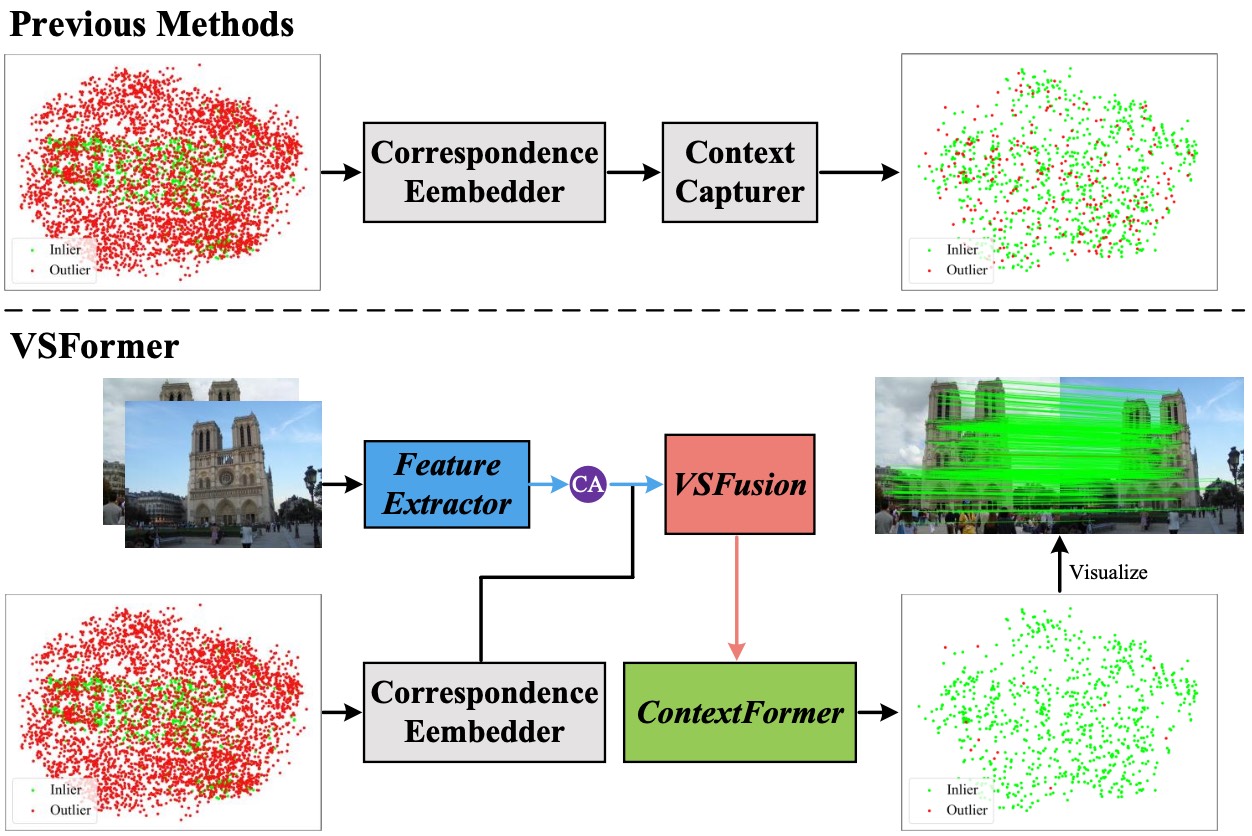
Correspondence pruning aims to find correct matches (inliers) from an initial set of putative correspondences, which is a fundamental task for many applications. The process of finding is challenging, given the varying inlier ratios between scenes/image pairs due to significant visual differences. However, the performance of the existing methods is usually limited by the problem of lacking visual cues (\eg texture, illumination, structure) of scenes. In this paper, we propose a Visual-Spatial Fusion Transformer (VSFormer) to identify inliers and recover camera poses accurately. Firstly, we obtain highly abstract visual cues of a scene with the cross attention between local features of two-view images. Then, we model these visual cues and correspondences by a joint visual-spatial fusion module, simultaneously embedding visual cues into correspondences for pruning. Additionally, to mine the consistency of correspondences, we also design a novel module that combines the KNN-based graph and the transformer, effectively capturing both local and global contexts. Extensive experiments have demonstrated that the proposed VSFormer outperforms state-of-the-art methods on outdoor and indoor benchmarks. Our code is provided at the following repository: https://github.com/sugar-fly/VSFormer.
PDF Abstract
 YFCC100M
YFCC100M
 SUN3D
SUN3D
