Vote2Cap-DETR++: Decoupling Localization and Describing for End-to-End 3D Dense Captioning
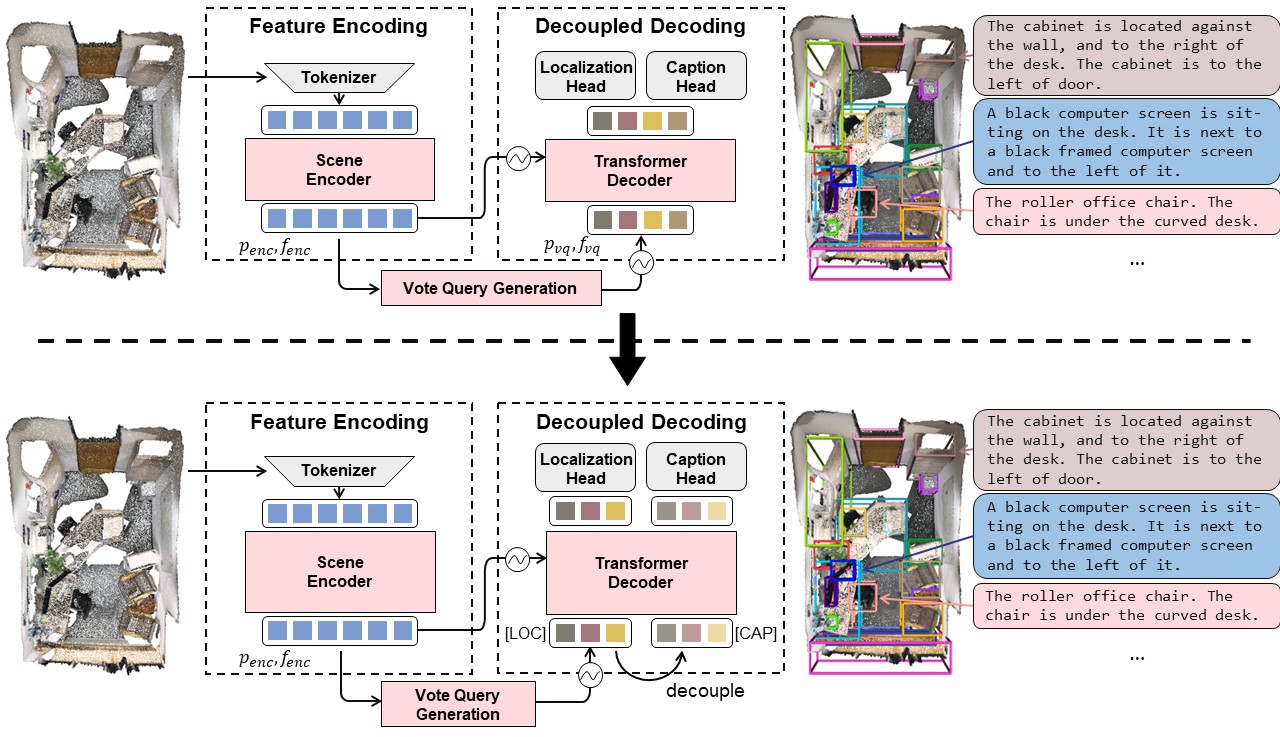
3D dense captioning requires a model to translate its understanding of an input 3D scene into several captions associated with different object regions. Existing methods adopt a sophisticated "detect-then-describe" pipeline, which builds explicit relation modules upon a 3D detector with numerous hand-crafted components. While these methods have achieved initial success, the cascade pipeline tends to accumulate errors because of duplicated and inaccurate box estimations and messy 3D scenes. In this paper, we first propose Vote2Cap-DETR, a simple-yet-effective transformer framework that decouples the decoding process of caption generation and object localization through parallel decoding. Moreover, we argue that object localization and description generation require different levels of scene understanding, which could be challenging for a shared set of queries to capture. To this end, we propose an advanced version, Vote2Cap-DETR++, which decouples the queries into localization and caption queries to capture task-specific features. Additionally, we introduce the iterative spatial refinement strategy to vote queries for faster convergence and better localization performance. We also insert additional spatial information to the caption head for more accurate descriptions. Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate Vote2Cap-DETR and Vote2Cap-DETR++ surpass conventional "detect-then-describe" methods by a large margin. Codes will be made available at https://github.com/ch3cook-fdu/Vote2Cap-DETR.
PDF Abstract

 ScanNet
ScanNet
