Vocal Style Factorization for Effective Speaker Recognition in Affective Scenarios
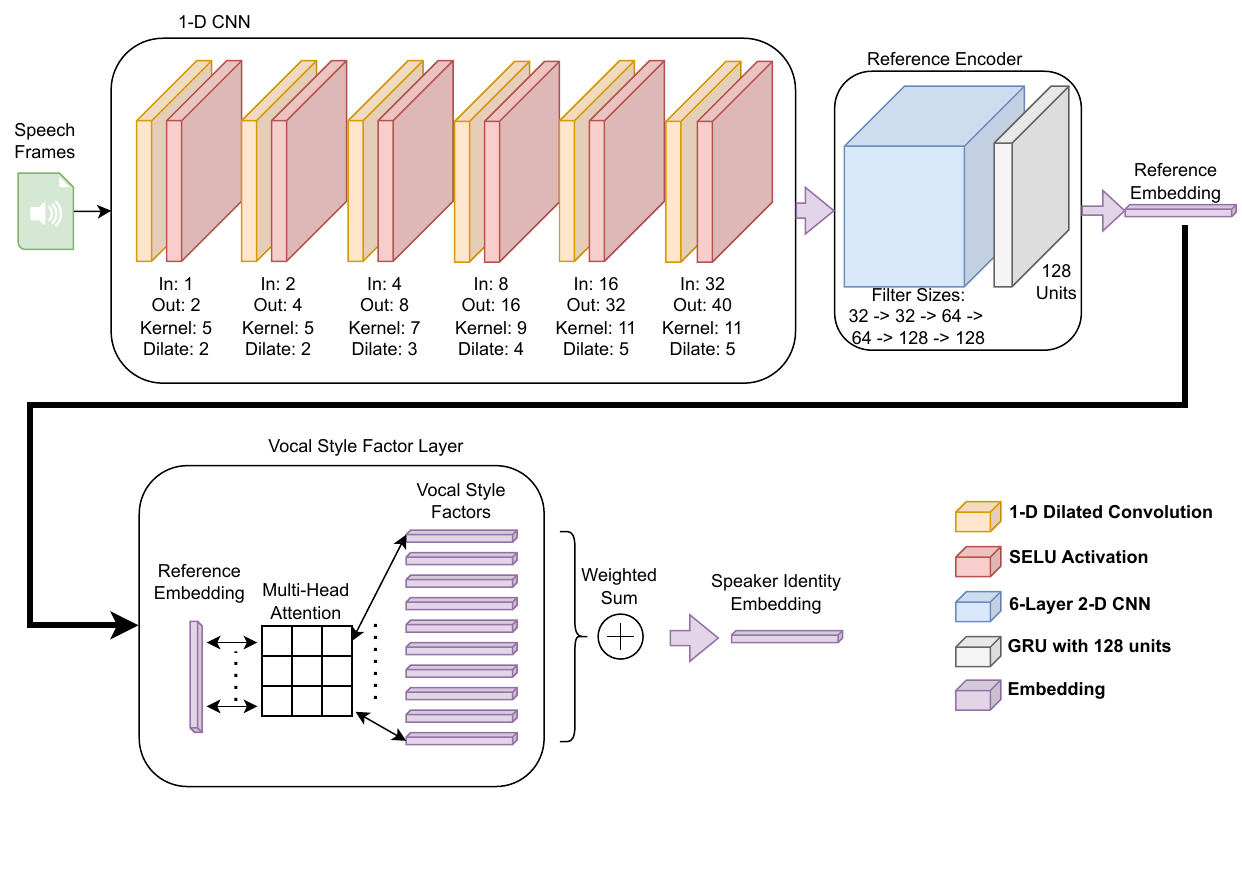
The accuracy of automated speaker recognition is negatively impacted by change in emotions in a person's speech. In this paper, we hypothesize that speaker identity is composed of various vocal style factors that may be learned from unlabeled data and re-combined using a neural network to generate a holistic speaker identity representation for affective scenarios. In this regard, we propose the E-Vector architecture, composed of a 1-D CNN for learning speaker identity features and a vocal style factorization technique for determining vocal styles. Experiments conducted on the MSP-Podcast dataset demonstrate that the proposed architecture improves state-of-the-art speaker recognition accuracy in the affective domain over baseline ECAPA-TDNN speaker recognition models. For instance, the true match rate at a false match rate of 1% improves from 27.6% to 46.2%.
PDF Abstract
