VMamba: Visual State Space Model
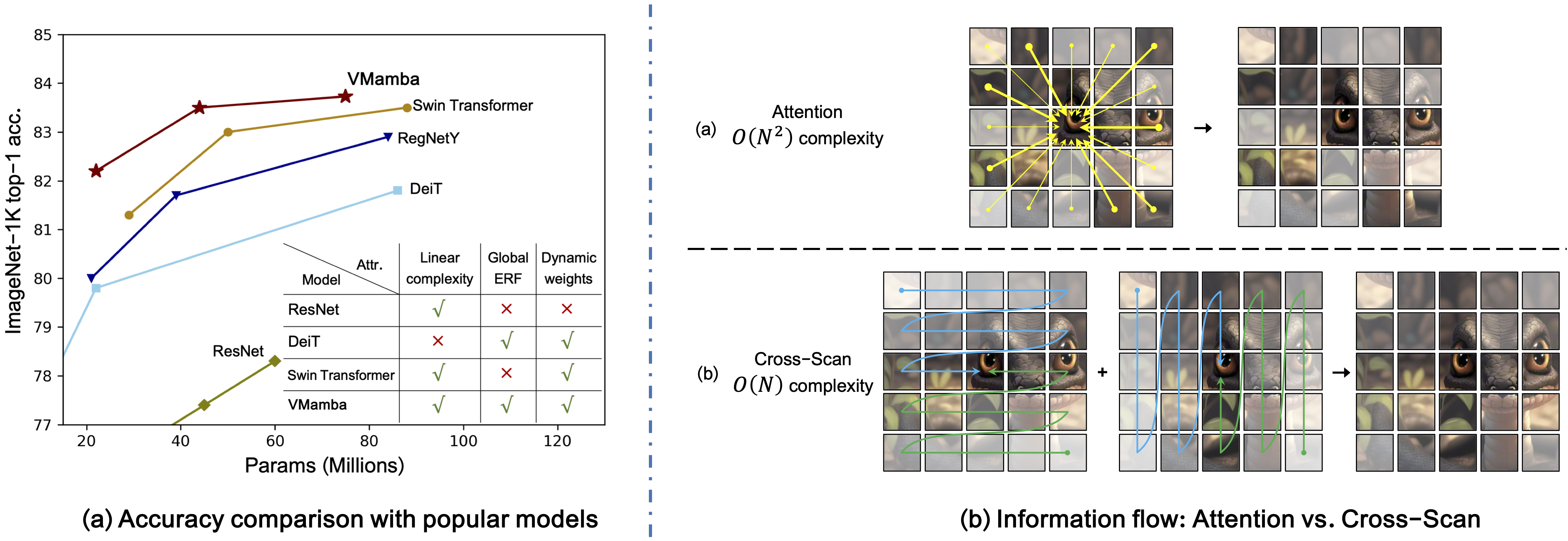
Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) have long been the predominant backbone networks for visual representation learning. While ViTs have recently gained prominence over CNNs due to their superior fitting capabilities, their scalability is largely constrained by the quadratic complexity of attention computation. Inspired by the capability of Mamba in efficiently modeling long sequences, we propose VMamba, a generic vision backbone model aiming to reduce the computational complexity to linear while retaining ViTs' advantageous features. To enhance VMamba's adaptability in processing vision data, we introduce the Cross-Scan Module (CSM) to enable 1D selective scanning in 2D image space with global receptive fields. Additionally, we make further improvements in implementation details and architectural designs to enhance VMamba's performance and boost its inference speed. Extensive experimental results demonstrate VMamba's promising performance across various visual perception tasks, highlighting its pronounced advantages in input scaling efficiency compared to existing benchmark models. Source code is available at https://github.com/MzeroMiko/VMamba.
PDF Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
