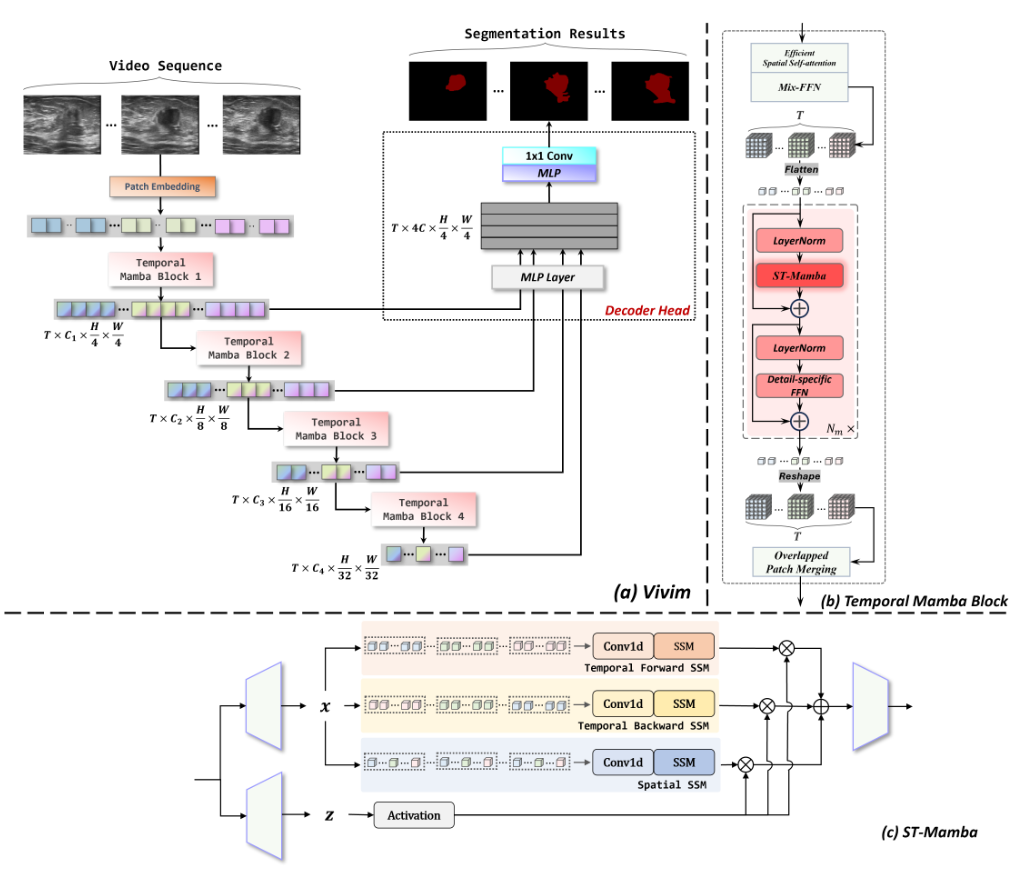
Vivim: a Video Vision Mamba for Medical Video Object Segmentation
Traditional convolutional neural networks have a limited receptive field while transformer-based networks are mediocre in constructing long-term dependency from the perspective of computational complexity. Such the bottleneck poses a significant challenge when processing long sequences in video analysis tasks. Very recently, the state space models (SSMs) with efficient hardware-aware designs, famous by Mamba, have exhibited impressive achievements in long sequence modeling, which facilitates the development of deep neural networks on many vision tasks. To better capture available dynamic cues in video frames, this paper presents a generic Video Vision Mamba-based framework, dubbed as \textbf{Vivim}, for medical video object segmentation tasks. Our Vivim can effectively compress the long-term spatiotemporal representation into sequences at varying scales by our designed Temporal Mamba Block. We also introduce a boundary-aware constraint to enhance the discriminative ability of Vivim on ambiguous lesions in medical images. Extensive experiments on thyroid segmentation in ultrasound videos and polyp segmentation in colonoscopy videos demonstrate the effectiveness and efficiency of our Vivim, superior to existing methods. The code is available at: https://github.com/scott-yjyang/Vivim.
PDF Abstract




