ViTOL: Vision Transformer for Weakly Supervised Object Localization
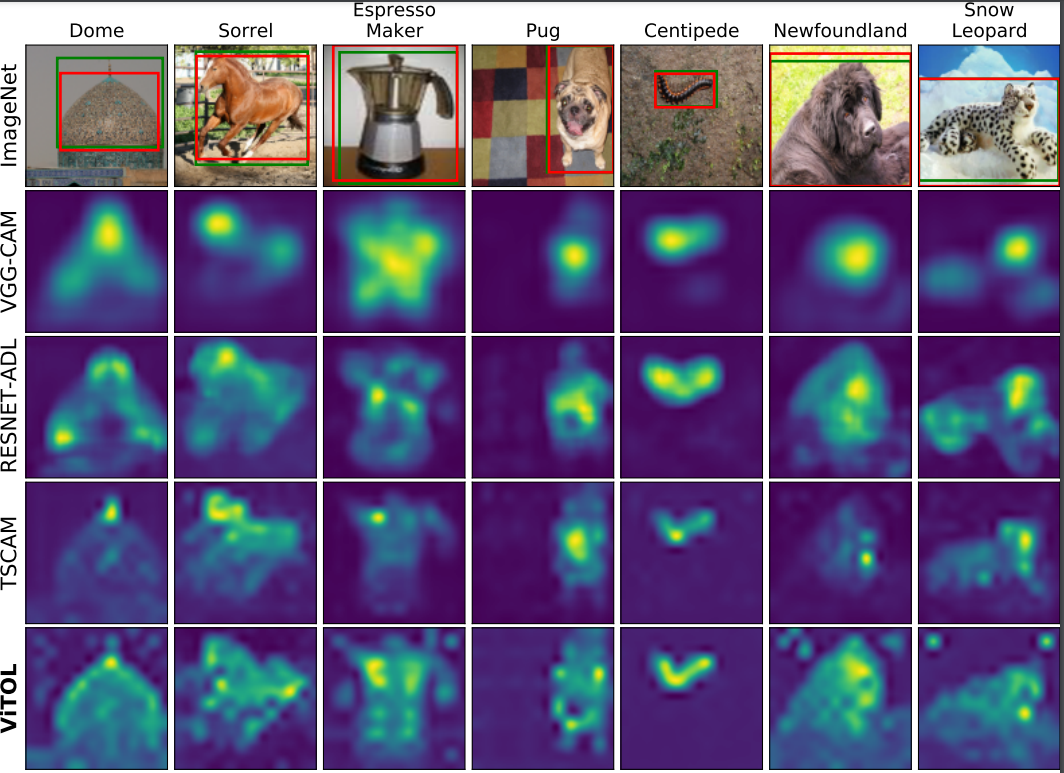
Weakly supervised object localization (WSOL) aims at predicting object locations in an image using only image-level category labels. Common challenges that image classification models encounter when localizing objects are, (a) they tend to look at the most discriminative features in an image that confines the localization map to a very small region, (b) the localization maps are class agnostic, and the models highlight objects of multiple classes in the same image and, (c) the localization performance is affected by background noise. To alleviate the above challenges we introduce the following simple changes through our proposed method ViTOL. We leverage the vision-based transformer for self-attention and introduce a patch-based attention dropout layer (p-ADL) to increase the coverage of the localization map and a gradient attention rollout mechanism to generate class-dependent attention maps. We conduct extensive quantitative, qualitative and ablation experiments on the ImageNet-1K and CUB datasets. We achieve state-of-the-art MaxBoxAcc-V2 localization scores of 70.47% and 73.17% on the two datasets respectively. Code is available on https://github.com/Saurav-31/ViTOL
PDF Abstract


 ImageNet
ImageNet
 CUB-200-2011
CUB-200-2011
