Visual Relation Grounding in Videos
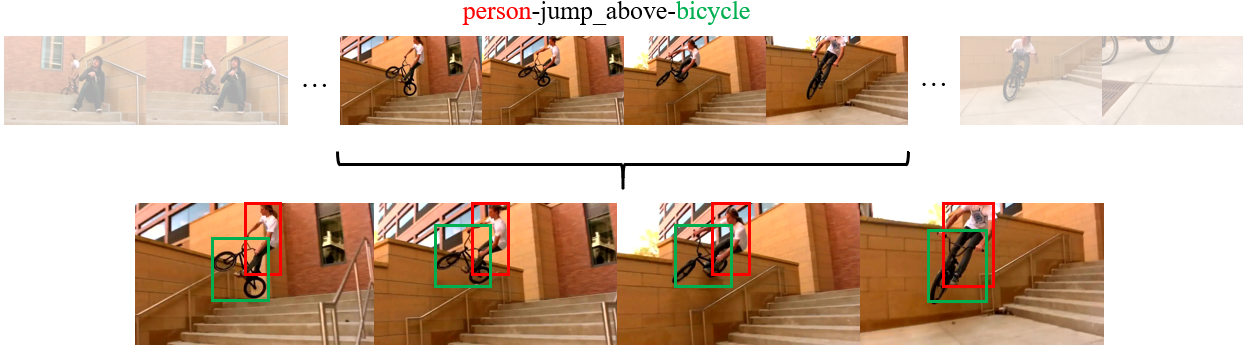
In this paper, we explore a novel task named visual Relation Grounding in Videos (vRGV). The task aims at spatio-temporally localizing the given relations in the form of subject-predicate-object in the videos, so as to provide supportive visual facts for other high-level video-language tasks (e.g., video-language grounding and video question answering). The challenges in this task include but not limited to: (1) both the subject and object are required to be spatio-temporally localized to ground a query relation; (2) the temporal dynamic nature of visual relations in videos is difficult to capture; and (3) the grounding should be achieved without any direct supervision in space and time. To ground the relations, we tackle the challenges by collaboratively optimizing two sequences of regions over a constructed hierarchical spatio-temporal region graph through relation attending and reconstruction, in which we further propose a message passing mechanism by spatial attention shifting between visual entities. Experimental results demonstrate that our model can not only outperform baseline approaches significantly, but also produces visually meaningful facts to support visual grounding. (Code is available at https://github.com/doc-doc/vRGV).
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract



 VRD
VRD
