ViStripformer: A Token-Efficient Transformer for Versatile Video Restoration
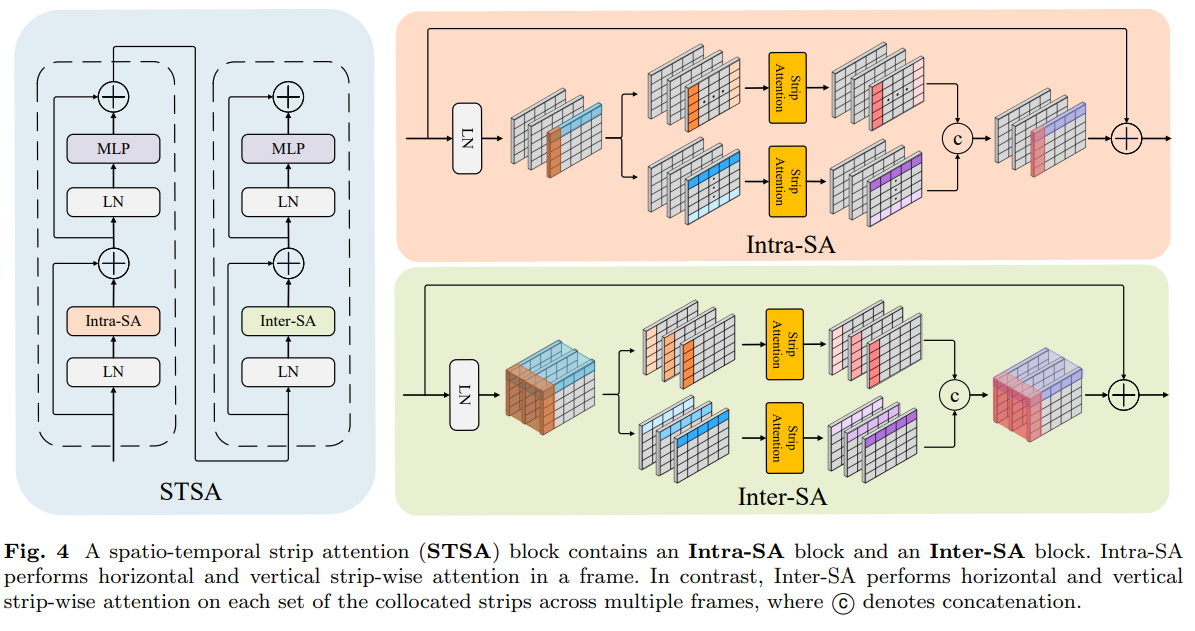
Video restoration is a low-level vision task that seeks to restore clean, sharp videos from quality-degraded frames. One would use the temporal information from adjacent frames to make video restoration successful. Recently, the success of the Transformer has raised awareness in the computer-vision community. However, its self-attention mechanism requires much memory, which is unsuitable for high-resolution vision tasks like video restoration. In this paper, we propose ViStripformer (Video Stripformer), which utilizes spatio-temporal strip attention to catch long-range data correlations, consisting of intra-frame strip attention (Intra-SA) and inter-frame strip attention (Inter-SA) for extracting spatial and temporal information. It decomposes video frames into strip-shaped features in horizontal and vertical directions for Intra-SA and Inter-SA to address degradation patterns with various orientations and magnitudes. Besides, ViStripformer is an effective and efficient transformer architecture with much lower memory usage than the vanilla transformer. Extensive experiments show that the proposed model achieves superior results with fast inference time on video restoration tasks, including video deblurring, demoireing, and deraining.
PDF Abstract


 GoPro
GoPro
