VISION DIFFMASK: Faithful Interpretation of Vision Transformers with Differentiable Patch Masking
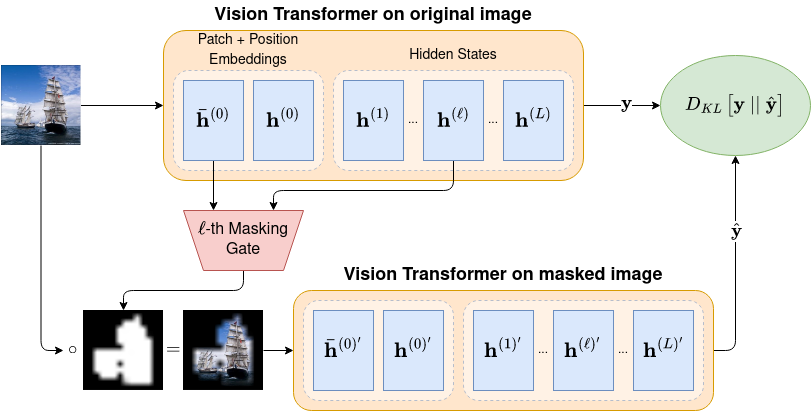
The lack of interpretability of the Vision Transformer may hinder its use in critical real-world applications despite its effectiveness. To overcome this issue, we propose a post-hoc interpretability method called VISION DIFFMASK, which uses the activations of the model's hidden layers to predict the relevant parts of the input that contribute to its final predictions. Our approach uses a gating mechanism to identify the minimal subset of the original input that preserves the predicted distribution over classes. We demonstrate the faithfulness of our method, by introducing a faithfulness task, and comparing it to other state-of-the-art attribution methods on CIFAR-10 and ImageNet-1K, achieving compelling results. To aid reproducibility and further extension of our work, we open source our implementation: https://github.com/AngelosNal/Vision-DiffMask
PDF Abstract Spaces
Spaces

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
