VIPTR: A Vision Permutable Extractor for Fast and Efficient Scene Text Recognition
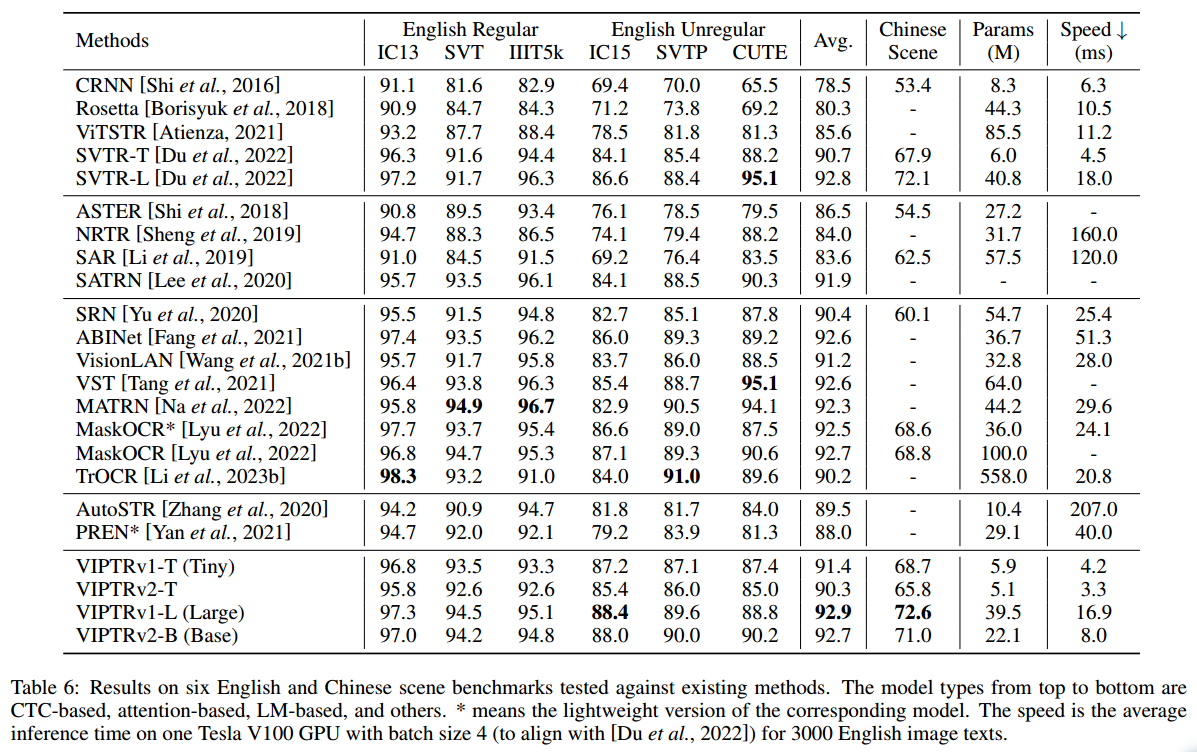
Scene Text Recognition (STR) is a challenging task that involves recognizing text within images of natural scenes. Although current state-of-the-art models for STR exhibit high performance, they typically suffer from low inference efficiency due to their reliance on hybrid architectures comprised of visual encoders and sequence decoders. In this work, we propose the VIsion Permutable extractor for fast and efficient scene Text Recognition (VIPTR), which achieves an impressive balance between high performance and rapid inference speeds in the domain of STR. Specifically, VIPTR leverages a visual-semantic extractor with a pyramid structure, characterized by multiple self-attention layers, while eschewing the traditional sequence decoder. This design choice results in a lightweight and efficient model capable of handling inputs of varying sizes. Extensive experimental results on various standard datasets for both Chinese and English scene text recognition validate the superiority of VIPTR. Notably, the VIPTR-T (Tiny) variant delivers highly competitive accuracy on par with other lightweight models and achieves SOTA inference speeds. Meanwhile, the VIPTR-L (Large) variant attains greater recognition accuracy, while maintaining a low parameter count and favorable inference speed. Our proposed method provides a compelling solution for the STR challenge, which blends high accuracy with efficiency and greatly benefits real-world applications requiring fast and reliable text recognition. The code is publicly available at https://github.com/cxfyxl/VIPTR.
PDF Abstract

