ViP: A Differentially Private Foundation Model for Computer Vision
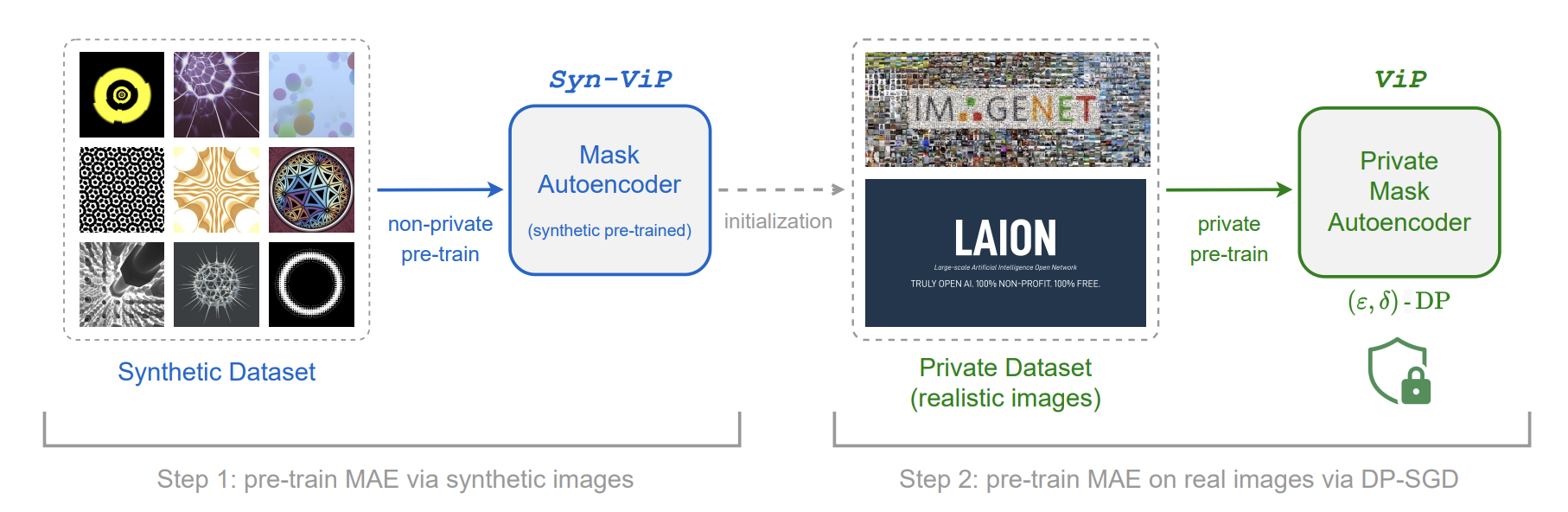
Artificial intelligence (AI) has seen a tremendous surge in capabilities thanks to the use of foundation models trained on internet-scale data. On the flip side, the uncurated nature of internet-scale data also poses significant privacy and legal risks, as they often contain personal information or copyrighted material that should not be trained on without permission. In this work, we propose as a mitigation measure a recipe to train foundation vision models with differential privacy (DP) guarantee. We identify masked autoencoders as a suitable learning algorithm that aligns well with DP-SGD, and train ViP -- a Vision transformer with differential Privacy -- under a strict privacy budget of $\epsilon=8$ on the LAION400M dataset. We evaluate the quality of representation learned by ViP using standard downstream vision tasks; in particular, ViP achieves a (non-private) linear probing accuracy of $55.7\%$ on ImageNet, comparable to that of end-to-end trained AlexNet (trained and evaluated on ImageNet). Our result suggests that scaling to internet-scale data can be practical for private learning. Code is available at \url{https://github.com/facebookresearch/ViP-MAE}.
PDF Abstract
 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Places205
Places205
 iNaturalist
iNaturalist
 LAION-400M
LAION-400M
