VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
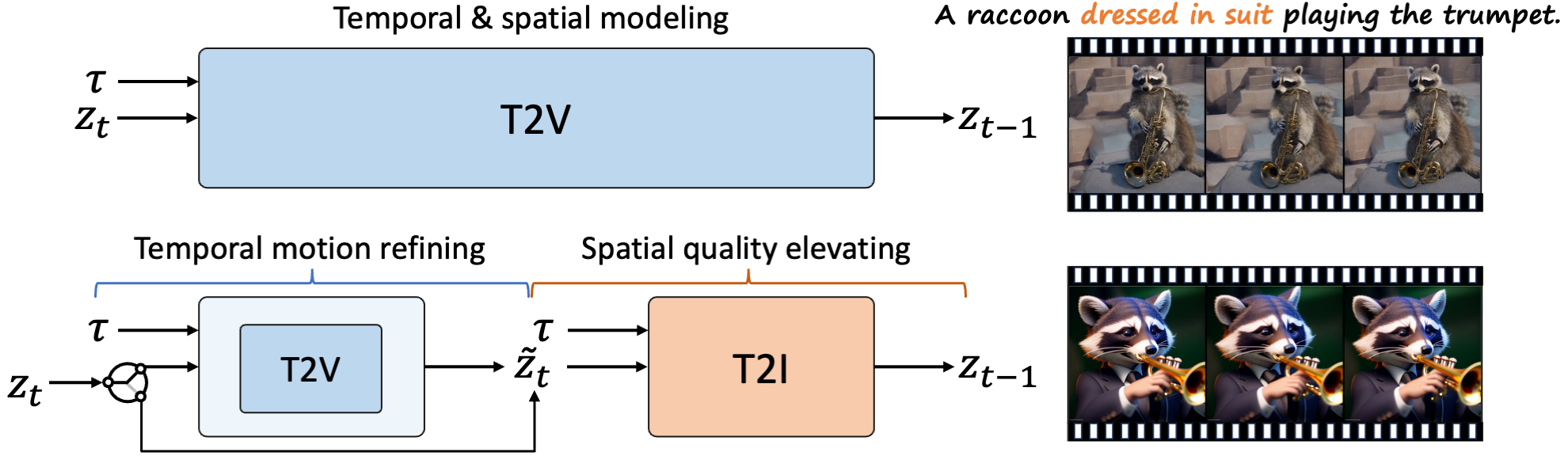
Text-to-image diffusion models (T2I) have demonstrated unprecedented capabilities in creating realistic and aesthetic images. On the contrary, text-to-video diffusion models (T2V) still lag far behind in frame quality and text alignment, owing to insufficient quality and quantity of training videos. In this paper, we introduce VideoElevator, a training-free and plug-and-play method, which elevates the performance of T2V using superior capabilities of T2I. Different from conventional T2V sampling (i.e., temporal and spatial modeling), VideoElevator explicitly decomposes each sampling step into temporal motion refining and spatial quality elevating. Specifically, temporal motion refining uses encapsulated T2V to enhance temporal consistency, followed by inverting to the noise distribution required by T2I. Then, spatial quality elevating harnesses inflated T2I to directly predict less noisy latent, adding more photo-realistic details. We have conducted experiments in extensive prompts under the combination of various T2V and T2I. The results show that VideoElevator not only improves the performance of T2V baselines with foundational T2I, but also facilitates stylistic video synthesis with personalized T2I. Our code is available at https://github.com/YBYBZhang/VideoElevator.
PDF Abstract

