Video Representation Learning by Dense Predictive Coding
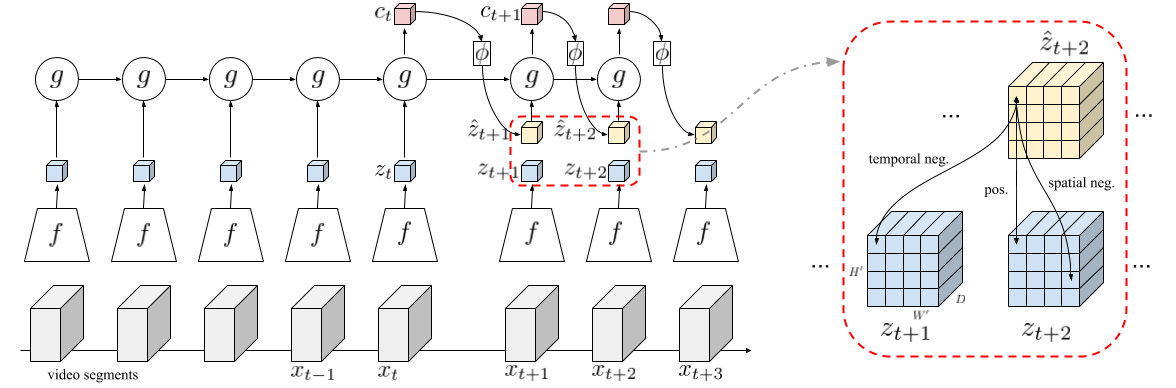
The objective of this paper is self-supervised learning of spatio-temporal embeddings from video, suitable for human action recognition. We make three contributions: First, we introduce the Dense Predictive Coding (DPC) framework for self-supervised representation learning on videos. This learns a dense encoding of spatio-temporal blocks by recurrently predicting future representations; Second, we propose a curriculum training scheme to predict further into the future with progressively less temporal context. This encourages the model to only encode slowly varying spatial-temporal signals, therefore leading to semantic representations; Third, we evaluate the approach by first training the DPC model on the Kinetics-400 dataset with self-supervised learning, and then finetuning the representation on a downstream task, i.e. action recognition. With single stream (RGB only), DPC pretrained representations achieve state-of-the-art self-supervised performance on both UCF101(75.7% top1 acc) and HMDB51(35.7% top1 acc), outperforming all previous learning methods by a significant margin, and approaching the performance of a baseline pre-trained on ImageNet.
PDF Abstract





 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51
 Kinetics 400
Kinetics 400

