Video Instance Segmentation using Inter-Frame Communication Transformers
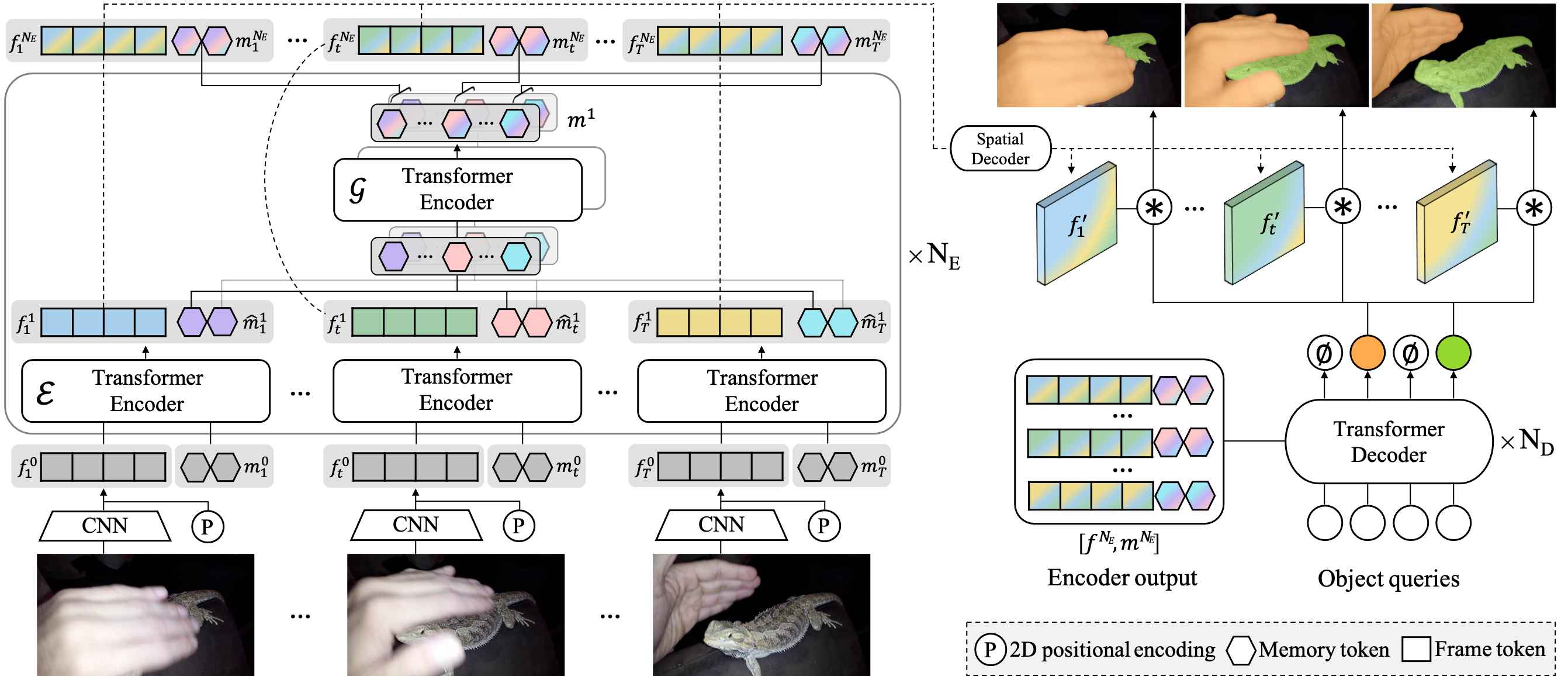
We propose a novel end-to-end solution for video instance segmentation (VIS) based on transformers. Recently, the per-clip pipeline shows superior performance over per-frame methods leveraging richer information from multiple frames. However, previous per-clip models require heavy computation and memory usage to achieve frame-to-frame communications, limiting practicality. In this work, we propose Inter-frame Communication Transformers (IFC), which significantly reduces the overhead for information-passing between frames by efficiently encoding the context within the input clip. Specifically, we propose to utilize concise memory tokens as a mean of conveying information as well as summarizing each frame scene. The features of each frame are enriched and correlated with other frames through exchange of information between the precisely encoded memory tokens. We validate our method on the latest benchmark sets and achieved the state-of-the-art performance (AP 44.6 on YouTube-VIS 2019 val set using the offline inference) while having a considerably fast runtime (89.4 FPS). Our method can also be applied to near-online inference for processing a video in real-time with only a small delay. The code will be made available.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract


 MS COCO
MS COCO
 YouTube-VIS 2019
YouTube-VIS 2019

