Video as Conditional Graph Hierarchy for Multi-Granular Question Answering
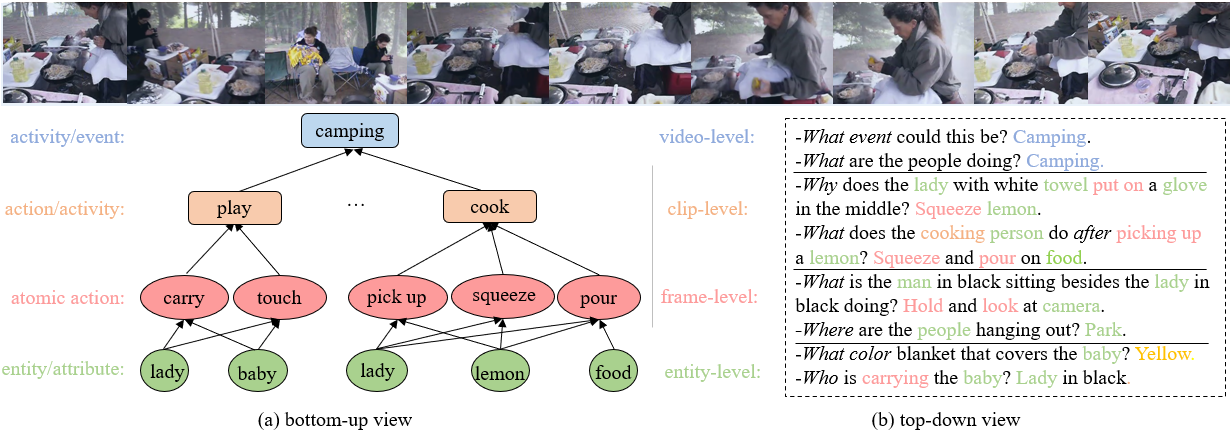
Video question answering requires the models to understand and reason about both the complex video and language data to correctly derive the answers. Existing efforts have been focused on designing sophisticated cross-modal interactions to fuse the information from two modalities, while encoding the video and question holistically as frame and word sequences. Despite their success, these methods are essentially revolving around the sequential nature of video- and question-contents, providing little insight to the problem of question-answering and lacking interpretability as well. In this work, we argue that while video is presented in frame sequence, the visual elements (e.g., objects, actions, activities and events) are not sequential but rather hierarchical in semantic space. To align with the multi-granular essence of linguistic concepts in language queries, we propose to model video as a conditional graph hierarchy which weaves together visual facts of different granularity in a level-wise manner, with the guidance of corresponding textual cues. Despite the simplicity, our extensive experiments demonstrate the superiority of such conditional hierarchical graph architecture, with clear performance improvements over prior methods and also better generalization across different type of questions. Further analyses also demonstrate the model's reliability as it shows meaningful visual-textual evidences for the predicted answers.
PDF Abstract



 NExT-QA
NExT-QA

