Variational Representation Learning for Vehicle Re-Identification
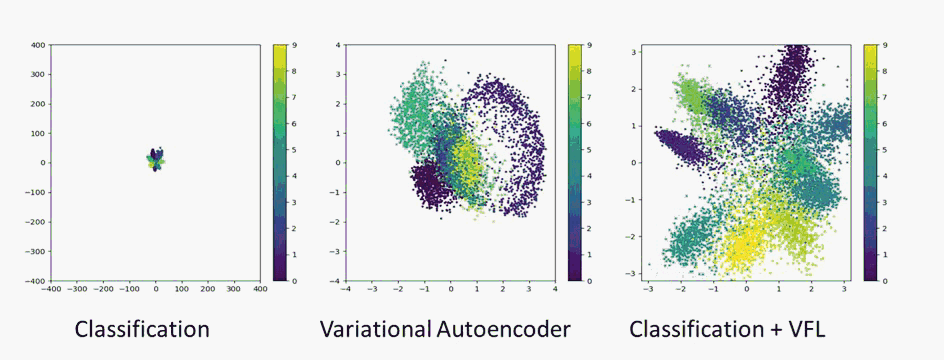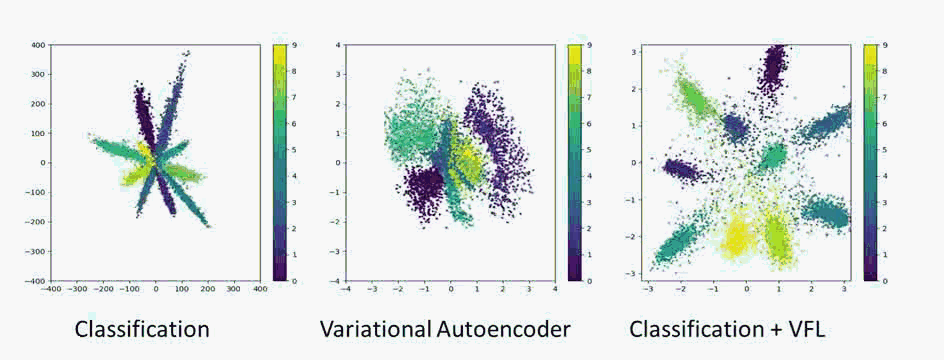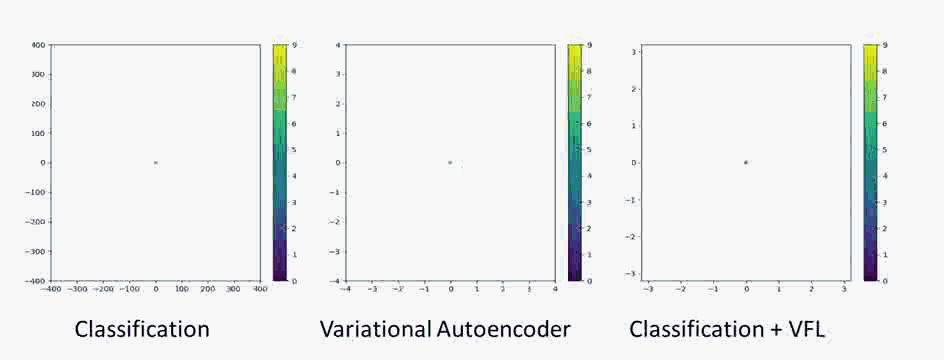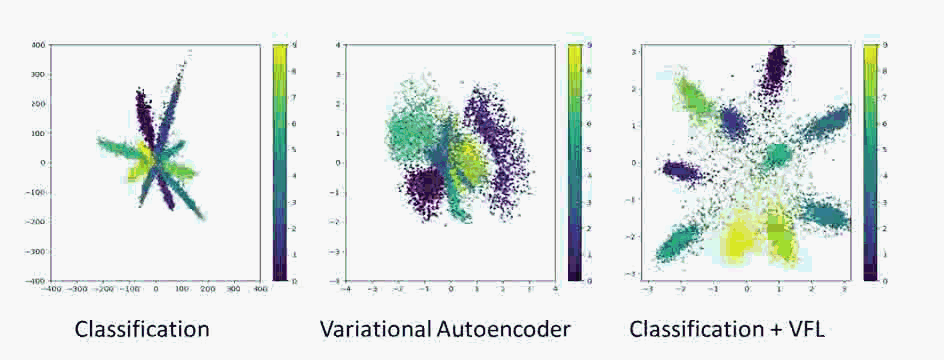
Vehicle Re-identification is attracting more and more attention in recent years. One of the most challenging problems is to learn an efficient representation for a vehicle from its multi-viewpoint images. Existing methods tend to derive features of dimensions ranging from thousands to tens of thousands. In this work we proposed a deep learning based framework that can lead to an efficient representation of vehicles. While the dimension of the learned features can be as low as 256, experiments on different datasets show that the Top-1 and Top-5 retrieval accuracies exceed multiple state-of-the-art methods. The key to our framework is two-fold. Firstly, variational feature learning is employed to generate variational features which are more discriminating. Secondly, long short-term memory (LSTM) is used to learn the relationship among different viewpoints of a vehicle. The LSTM also plays as an encoder to downsize the features.
PDF Abstract



 VehicleID
VehicleID
