Using Titles vs. Full-text as Source for Automated Semantic Document Annotation
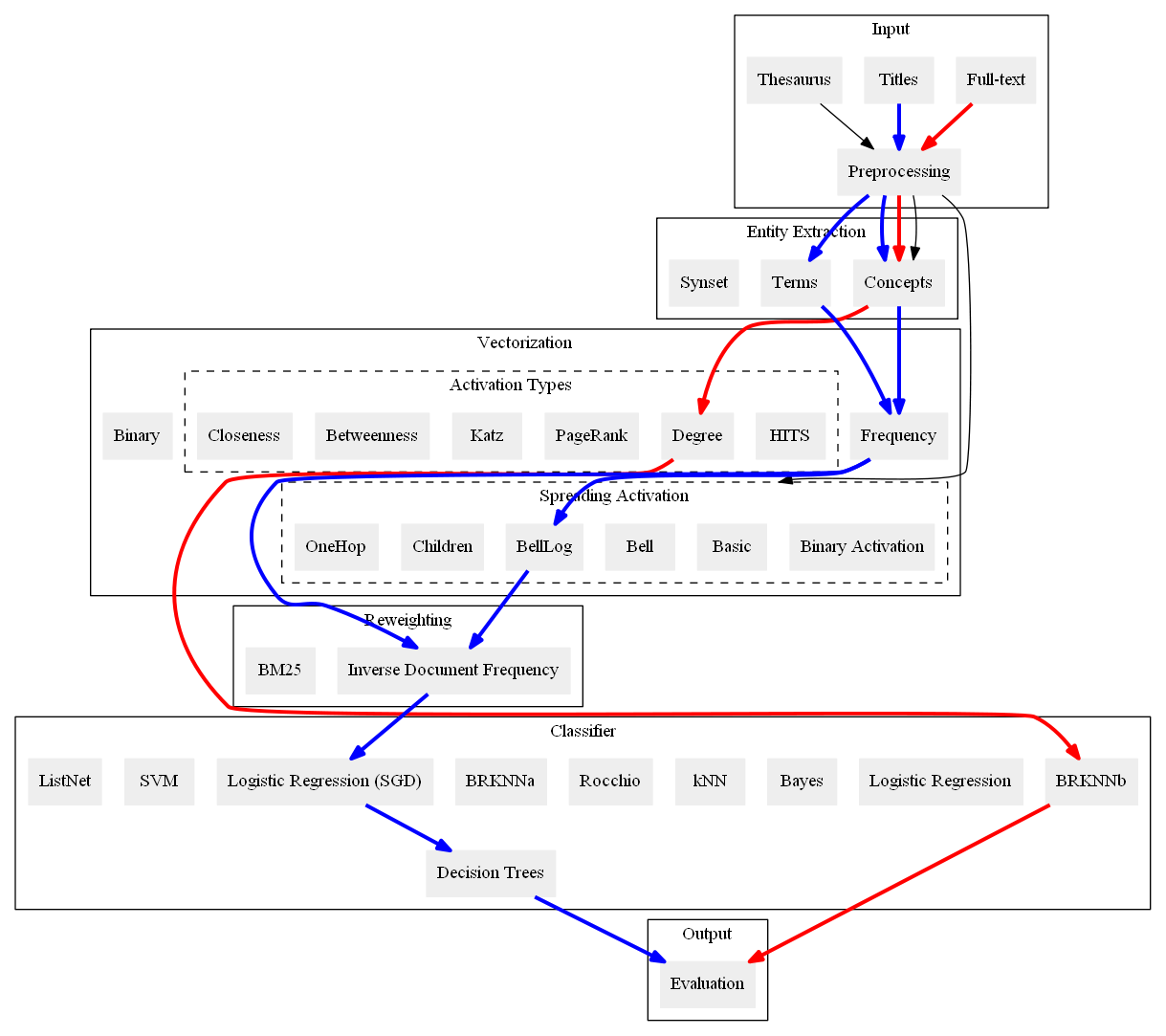
A significant part of the largest Knowledge Graph today, the Linked Open Data cloud, consists of metadata about documents such as publications, news reports, and other media articles. While the widespread access to the document metadata is a tremendous advancement, it is yet not so easy to assign semantic annotations and organize the documents along semantic concepts. Providing semantic annotations like concepts in SKOS thesauri is a classical research topic, but typically it is conducted on the full-text of the documents. For the first time, we offer a systematic comparison of classification approaches to investigate how far semantic annotations can be conducted using just the metadata of the documents such as titles published as labels on the Linked Open Data cloud. We compare the classifications obtained from analyzing the documents' titles with semantic annotations obtained from analyzing the full-text. Apart from the prominent text classification baselines kNN and SVM, we also compare recent techniques of Learning to Rank and neural networks and revisit the traditional methods logistic regression, Rocchio, and Naive Bayes. The results show that across three of our four datasets, the performance of the classifications using only titles reaches over 90% of the quality compared to the classification performance when using the full-text. Thus, conducting document classification by just using the titles is a reasonable approach for automated semantic annotation and opens up new possibilities for enriching Knowledge Graphs.
PDF Abstract




 RCV1
RCV1
