Using Pre-Training Can Improve Model Robustness and Uncertainty
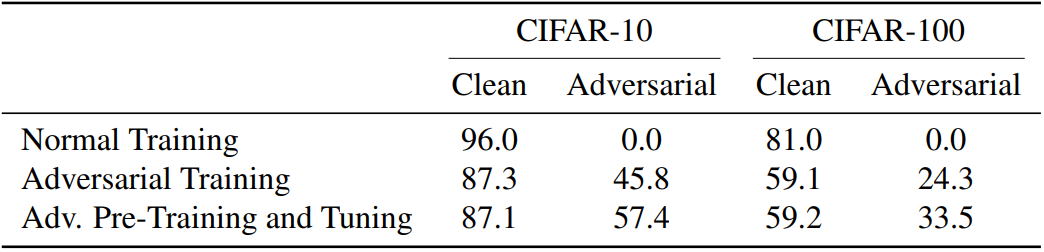
He et al. (2018) have called into question the utility of pre-training by showing that training from scratch can often yield similar performance to pre-training. We show that although pre-training may not improve performance on traditional classification metrics, it improves model robustness and uncertainty estimates. Through extensive experiments on adversarial examples, label corruption, class imbalance, out-of-distribution detection, and confidence calibration, we demonstrate large gains from pre-training and complementary effects with task-specific methods. We introduce adversarial pre-training and show approximately a 10% absolute improvement over the previous state-of-the-art in adversarial robustness. In some cases, using pre-training without task-specific methods also surpasses the state-of-the-art, highlighting the need for pre-training when evaluating future methods on robustness and uncertainty tasks.
PDF Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Places
Places
 Tiny ImageNet
Tiny ImageNet
