Towards Writer Retrieval for Historical Datasets
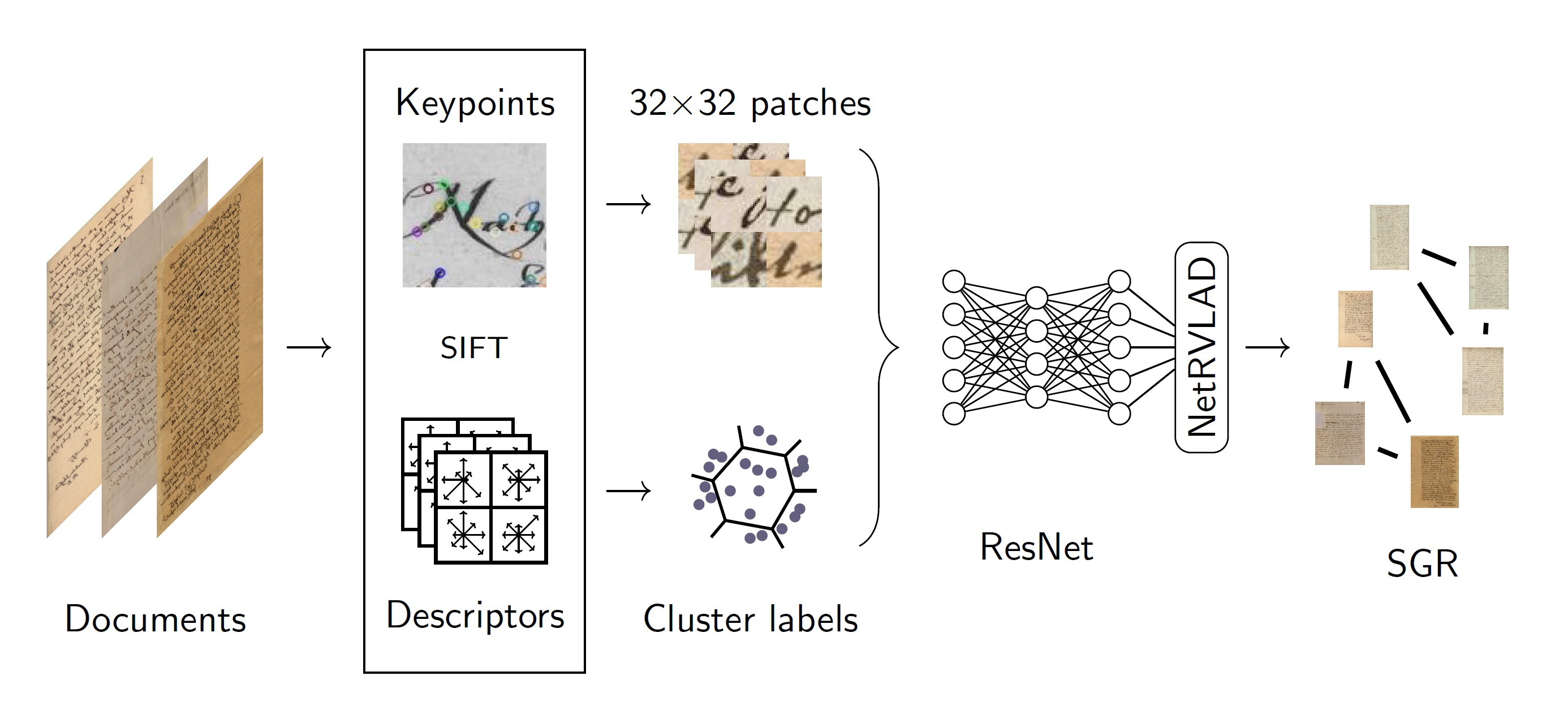
This paper presents an unsupervised approach for writer retrieval based on clustering SIFT descriptors detected at keypoint locations resulting in pseudo-cluster labels. With those cluster labels, a residual network followed by our proposed NetRVLAD, an encoding layer with reduced complexity compared to NetVLAD, is trained on 32x32 patches at keypoint locations. Additionally, we suggest a graph-based reranking algorithm called SGR to exploit similarities of the page embeddings to boost the retrieval performance. Our approach is evaluated on two historical datasets (Historical-WI and HisIR19). We include an evaluation of different backbones and NetRVLAD. It competes with related work on historical datasets without using explicit encodings. We set a new State-of-the-art on both datasets by applying our reranking scheme and show that our approach achieves comparable performance on a modern dataset as well.
PDF Abstract


