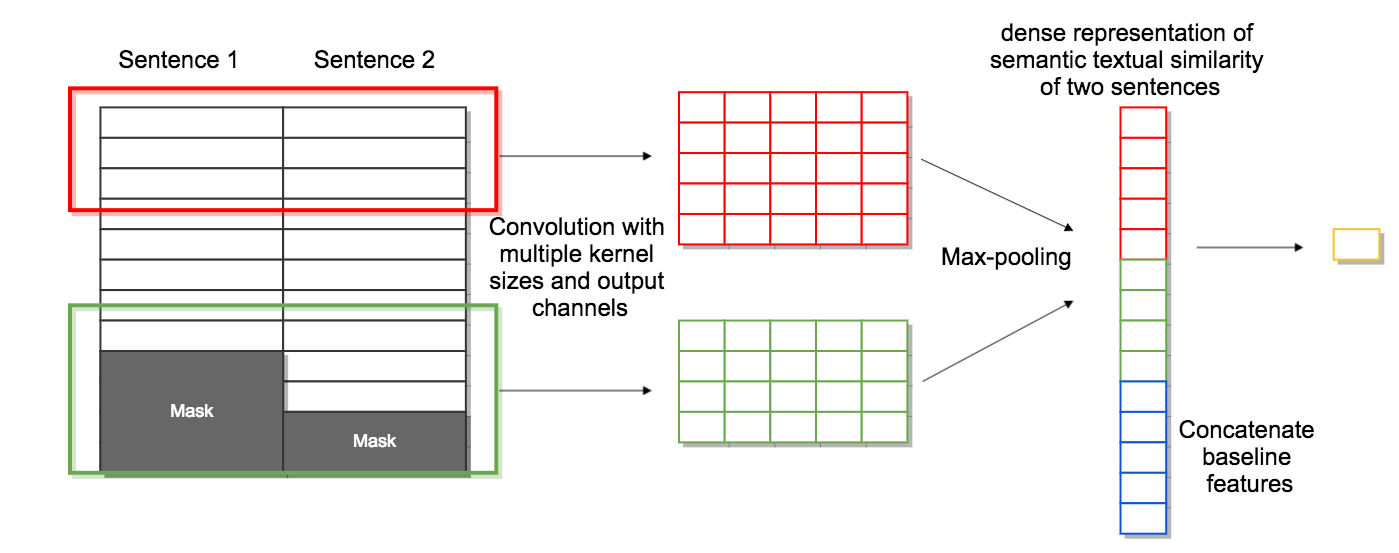
Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features
The recent tremendous success of unsupervised word embeddings in a multitude of applications raises the obvious question if similar methods could be derived to improve embeddings (i.e. semantic representations) of word sequences as well. We present a simple but efficient unsupervised objective to train distributed representations of sentences. Our method outperforms the state-of-the-art unsupervised models on most benchmark tasks, highlighting the robustness of the produced general-purpose sentence embeddings.
PDF Abstract NAACL 2018 PDF NAACL 2018 AbstractCode



Datasets
 SICK
SICK
 MPQA Opinion Corpus
MPQA Opinion Corpus
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
