Unsupervised Interpretable Representation Learning for Singing Voice Separation
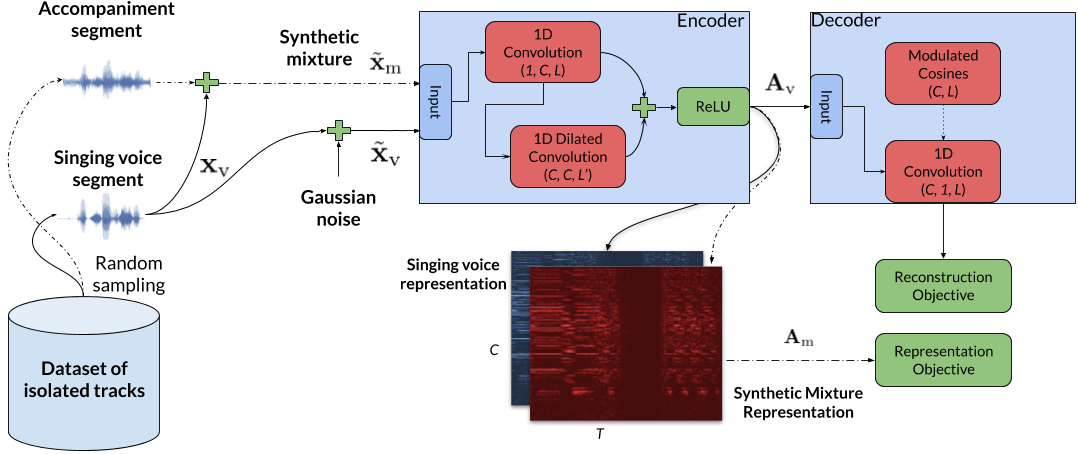
In this work, we present a method for learning interpretable music signal representations directly from waveform signals. Our method can be trained using unsupervised objectives and relies on the denoising auto-encoder model that uses a simple sinusoidal model as decoding functions to reconstruct the singing voice. To demonstrate the benefits of our method, we employ the obtained representations to the task of informed singing voice separation via binary masking, and measure the obtained separation quality by means of scale-invariant signal to distortion ratio. Our findings suggest that our method is capable of learning meaningful representations for singing voice separation, while preserving conveniences of the the short-time Fourier transform like non-negativity, smoothness, and reconstruction subject to time-frequency masking, that are desired in audio and music source separation.
PDF Abstract



