Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion
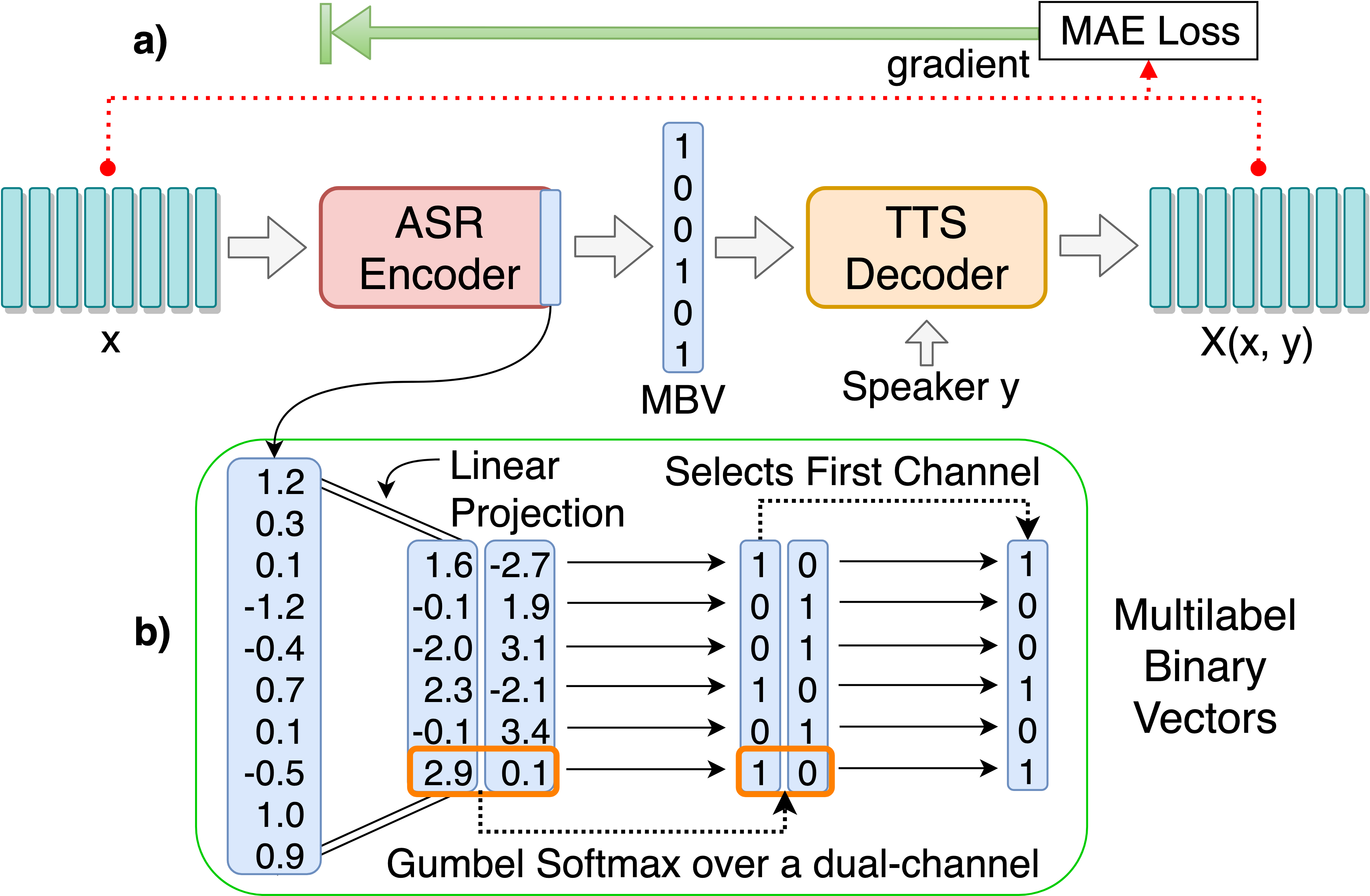
We present an unsupervised end-to-end training scheme where we discover discrete subword units from speech without using any labels. The discrete subword units are learned under an ASR-TTS autoencoder reconstruction setting, where an ASR-Encoder is trained to discover a set of common linguistic units given a variety of speakers, and a TTS-Decoder trained to project the discovered units back to the designated speech. We propose a discrete encoding method, Multilabel-Binary Vectors (MBV), to make the ASR-TTS autoencoder differentiable. We found that the proposed encoding method offers automatic extraction of speech content from speaker style, and is sufficient to cover full linguistic content in a given language. Therefore, the TTS-Decoder can synthesize speech with the same content as the input of ASR-Encoder but with different speaker characteristics, which achieves voice conversion (VC). We further improve the quality of VC using adversarial training, where we train a TTS-Patcher that augments the output of TTS-Decoder. Objective and subjective evaluations show that the proposed approach offers strong VC results as it eliminates speaker identity while preserving content within speech. In the ZeroSpeech 2019 Challenge, we achieved outstanding performance in terms of low bitrate.
PDF Abstract

