Unlocking Compositional Generalization in Pre-trained Models Using Intermediate Representations
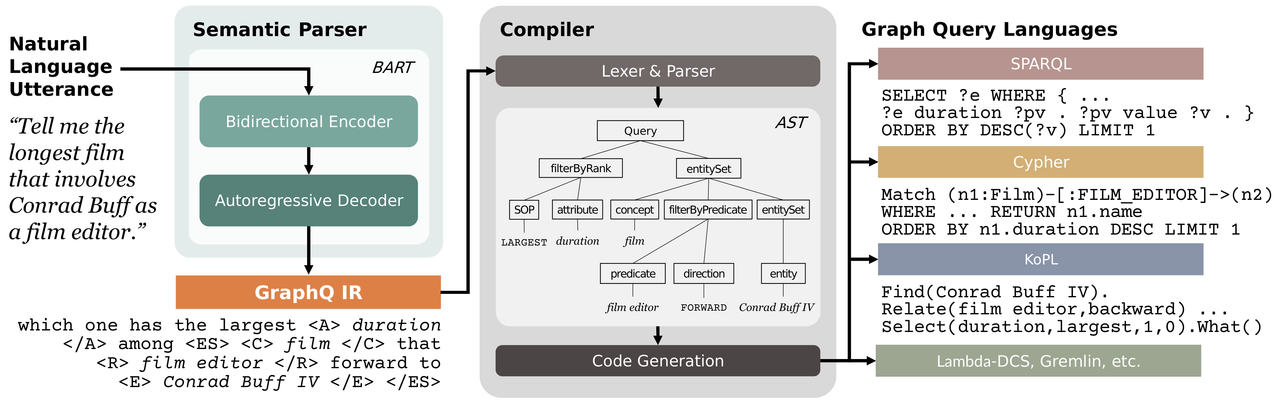
Sequence-to-sequence (seq2seq) models are prevalent in semantic parsing, but have been found to struggle at out-of-distribution compositional generalization. While specialized model architectures and pre-training of seq2seq models have been proposed to address this issue, the former often comes at the cost of generality and the latter only shows limited success. In this paper, we study the impact of intermediate representations on compositional generalization in pre-trained seq2seq models, without changing the model architecture at all, and identify key aspects for designing effective representations. Instead of training to directly map natural language to an executable form, we map to a reversible or lossy intermediate representation that has stronger structural correspondence with natural language. The combination of our proposed intermediate representations and pre-trained models is surprisingly effective, where the best combinations obtain a new state-of-the-art on CFQ (+14.8 accuracy points) and on the template-splits of three text-to-SQL datasets (+15.0 to +19.4 accuracy points). This work highlights that intermediate representations provide an important and potentially overlooked degree of freedom for improving the compositional generalization abilities of pre-trained seq2seq models.
PDF Abstract



 SCAN
SCAN
 SPIDER
SPIDER
 Spider
Spider

