MARVEL: Unlocking the Multi-Modal Capability of Dense Retrieval via Visual Module Plugin
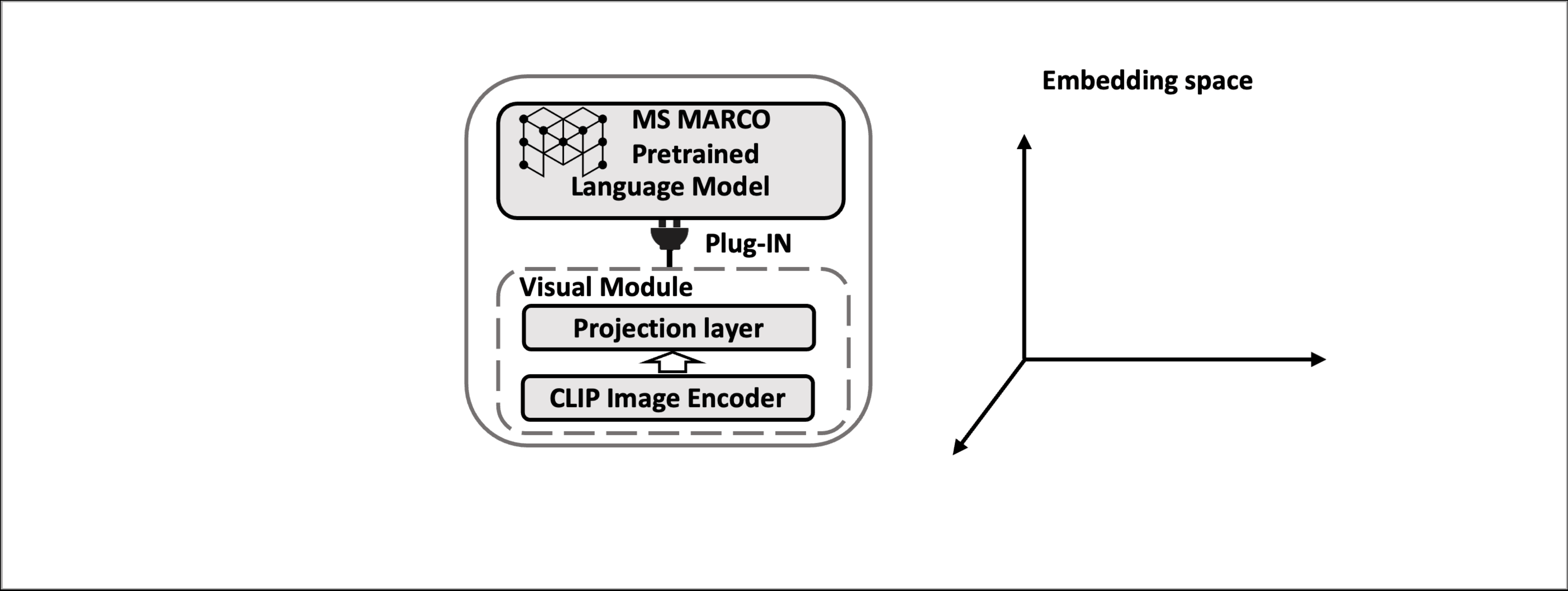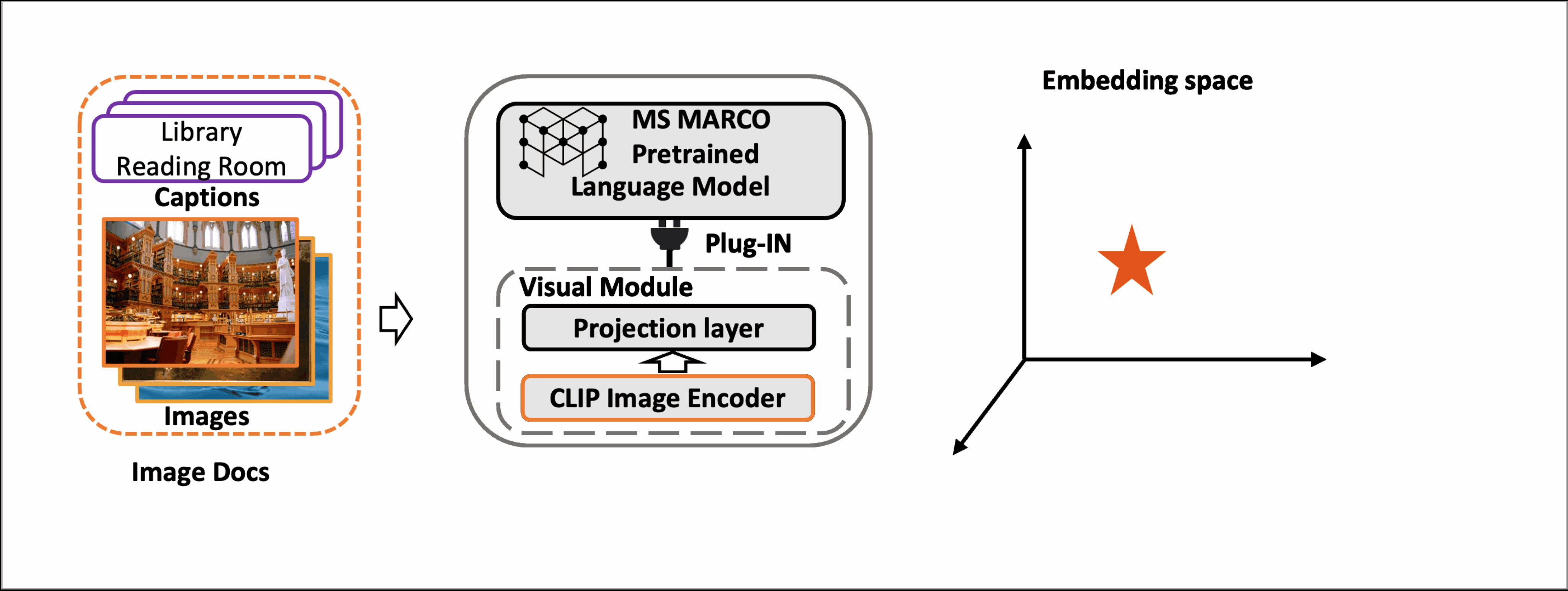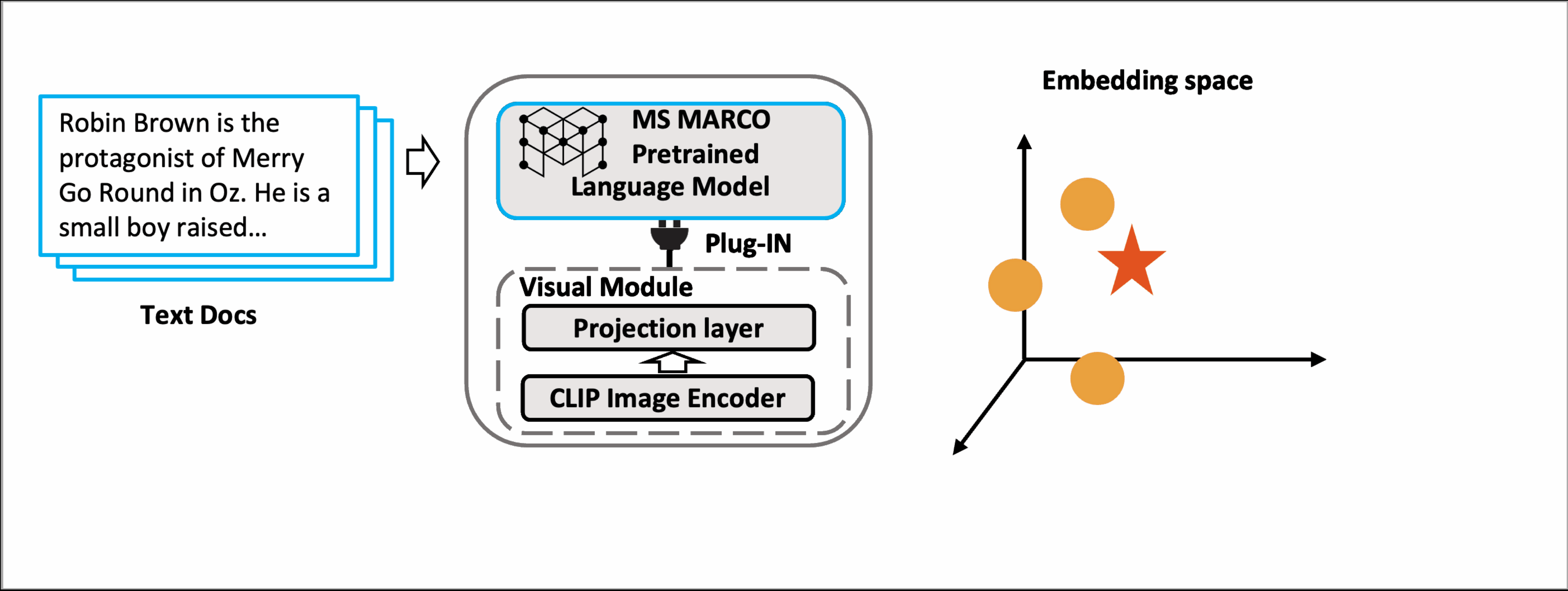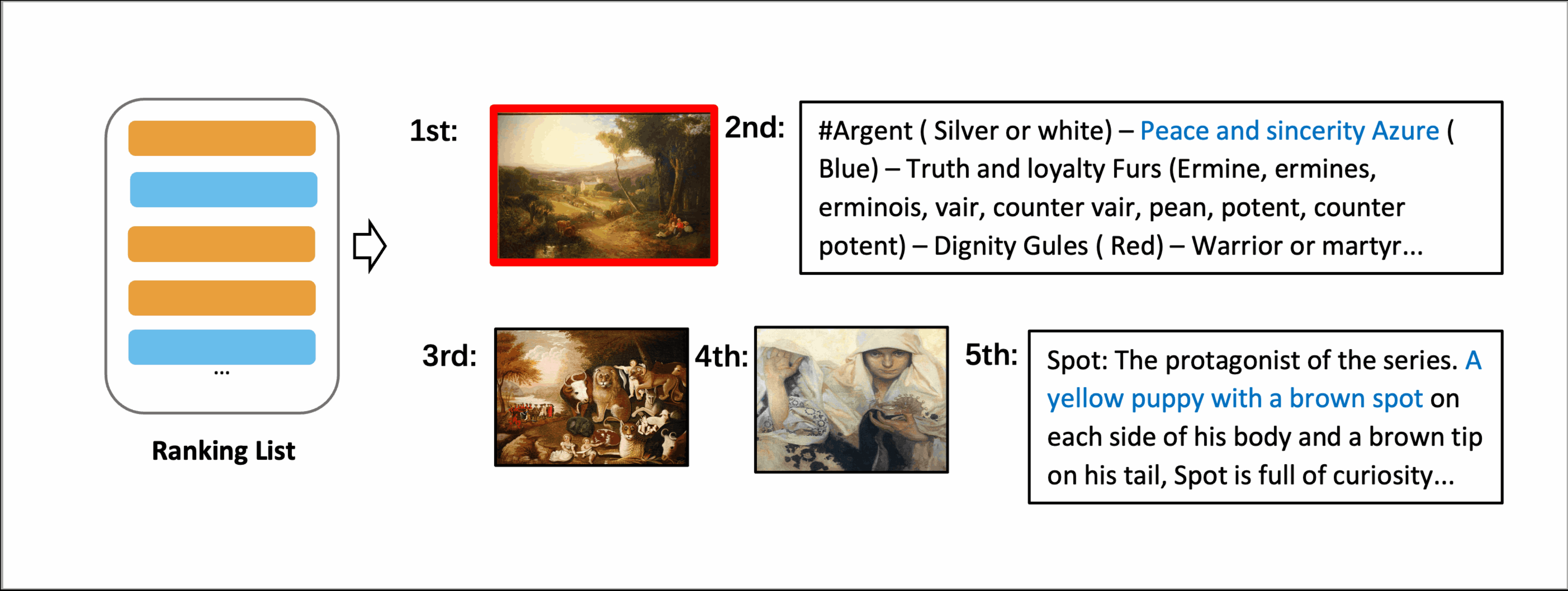
This paper proposes Multi-modAl Retrieval model via Visual modulE pLugin (MARVEL), which learns an embedding space for queries and multi-modal documents to conduct retrieval. MARVEL encodes queries and multi-modal documents with a unified encoder model, which helps to alleviate the modality gap between images and texts. Specifically, we enable the image understanding ability of the well-trained dense retriever, T5-ANCE, by incorporating the visual module's encoded image features as its inputs. To facilitate the multi-modal retrieval tasks, we build the ClueWeb22-MM dataset based on the ClueWeb22 dataset, which regards anchor texts as queries, and exacts the related text and image documents from anchor-linked web pages. Our experiments show that MARVEL significantly outperforms the state-of-the-art methods on the multi-modal retrieval dataset WebQA and ClueWeb22-MM. MARVEL provides an opportunity to broaden the advantages of text retrieval to the multi-model scenario. Besides, we also illustrate that the language model has the ability to extract image semantics and partly map the image features to the input word embedding space. All codes are available at https://github.com/OpenMatch/MARVEL.
PDF Abstract


 MS MARCO
MS MARCO
 WebQA
WebQA
