Unlearnable Examples Give a False Sense of Security: Piercing through Unexploitable Data with Learnable Examples
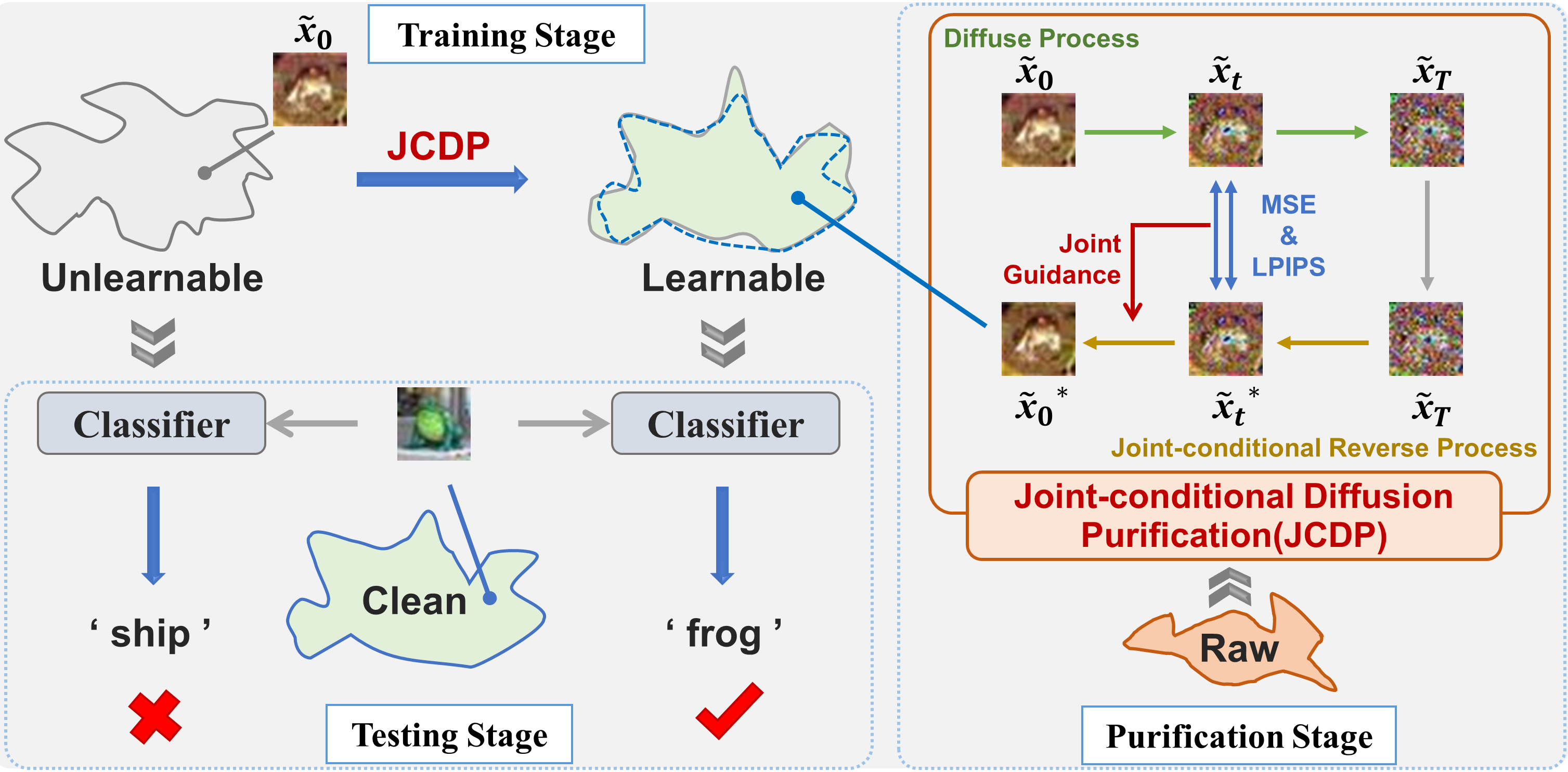
Safeguarding data from unauthorized exploitation is vital for privacy and security, especially in recent rampant research in security breach such as adversarial/membership attacks. To this end, \textit{unlearnable examples} (UEs) have been recently proposed as a compelling protection, by adding imperceptible perturbation to data so that models trained on them cannot classify them accurately on original clean distribution. Unfortunately, we find UEs provide a false sense of security, because they cannot stop unauthorized users from utilizing other unprotected data to remove the protection, by turning unlearnable data into learnable again. Motivated by this observation, we formally define a new threat by introducing \textit{learnable unauthorized examples} (LEs) which are UEs with their protection removed. The core of this approach is a novel purification process that projects UEs onto the manifold of LEs. This is realized by a new joint-conditional diffusion model which denoises UEs conditioned on the pixel and perceptual similarity between UEs and LEs. Extensive experiments demonstrate that LE delivers state-of-the-art countering performance against both supervised UEs and unsupervised UEs in various scenarios, which is the first generalizable countermeasure to UEs across supervised learning and unsupervised learning. Our code is available at \url{https://github.com/jiangw-0/LE_JCDP}.
PDF Abstract
 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 SVHN
SVHN
 Perceptual Similarity
Perceptual Similarity
