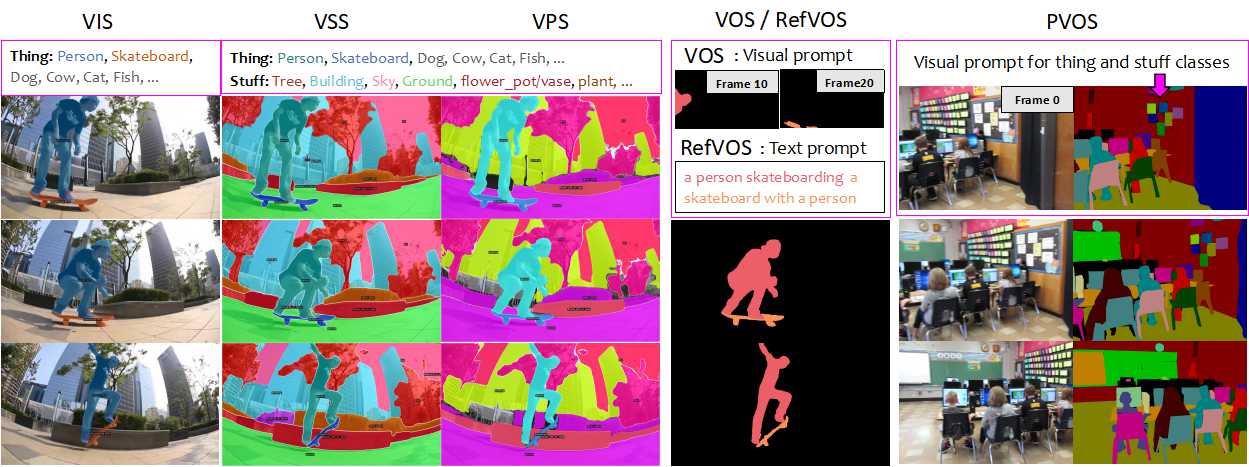
UniVS: Unified and Universal Video Segmentation with Prompts as Queries
Despite the recent advances in unified image segmentation (IS), developing a unified video segmentation (VS) model remains a challenge. This is mainly because generic category-specified VS tasks need to detect all objects and track them across consecutive frames, while prompt-guided VS tasks require re-identifying the target with visual/text prompts throughout the entire video, making it hard to handle the different tasks with the same architecture. We make an attempt to address these issues and present a novel unified VS architecture, namely UniVS, by using prompts as queries. UniVS averages the prompt features of the target from previous frames as its initial query to explicitly decode masks, and introduces a target-wise prompt cross-attention layer in the mask decoder to integrate prompt features in the memory pool. By taking the predicted masks of entities from previous frames as their visual prompts, UniVS converts different VS tasks into prompt-guided target segmentation, eliminating the heuristic inter-frame matching process. Our framework not only unifies the different VS tasks but also naturally achieves universal training and testing, ensuring robust performance across different scenarios. UniVS shows a commendable balance between performance and universality on 10 challenging VS benchmarks, covering video instance, semantic, panoptic, object, and referring segmentation tasks. Code can be found at \url{https://github.com/MinghanLi/UniVS}.
PDF AbstractCode





 DAVIS
DAVIS
 DAVIS 2017
DAVIS 2017
 YouTube-VOS 2018
YouTube-VOS 2018
 YouTube-VIS 2019
YouTube-VIS 2019
 Referring Expressions for DAVIS 2016 & 2017
Referring Expressions for DAVIS 2016 & 2017
 OVIS
OVIS
 Refer-YouTube-VOS
Refer-YouTube-VOS
Results from the Paper
 Ranked #2 on
Video Semantic Segmentation
on VSPW
(using extra training data)
Ranked #2 on
Video Semantic Segmentation
on VSPW
(using extra training data)
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Video Object Segmentation | DAVIS 2017 (val) | UniVS(Swin-L) | Mean Jaccard & F-Measure | 76.2 | # 14 | ||
| Jaccard | 72.8 | # 16 | |||||
| F-measure | 79.5 | # 15 | |||||
| Referring Expression Segmentation | DAVIS 2017 (val) | UniVS(Swin-L) | J&F 1st frame | 59.4? | # 14 | ||
| J&F Full video | 59.4 | # 1 | |||||
| Video Instance Segmentation | OVIS validation | UniVS(Swin-L) | mask AP | 41.7 | # 16 | ||
| Referring Expression Segmentation | Refer-YouTube-VOS (2021 public validation) | UniVS(Swin-L) | J&F | 58.0 | # 17 | ||
| J | 56.8 | # 16 | |||||
| F | 59.5 | # 16 | |||||
| Video Panoptic Segmentation | VIPSeg | UniVS(Swin-L) | VPQ | 49.3 | # 7 | ||
| STQ | 58.2 | # 1 | |||||
| Video Semantic Segmentation | VSPW | UniVS(Swin-L) | mIoU | 59.8 | # 2 | ||
| Video Instance Segmentation | YouTube-VIS 2021 | UniVS(Swin-L) | mask AP | 57.9 | # 10 | ||
| AP50 | 79.4 | # 12 | |||||
| AP75 | 63.3 | # 11 | |||||
| AR10 | 63.1 | # 10 | |||||
| AR1 | 46.2 | # 11 | |||||
| Video Instance Segmentation | YouTube-VIS validation | UniVS(Swin-L) | mask AP | 60.0 | # 15 | ||
| AP50 | 82.1 | # 14 | |||||
| AP75 | 65.3 | # 17 | |||||
| AR1 | 54.7 | # 11 | |||||
| AR10 | 66.8 | # 10 | |||||
| Video Object Segmentation | YouTube-VOS 2018 | UniVS(Swin-L) | Mean Jaccard & F-Measure | 71.5 | # 13 |
