UNITER: UNiversal Image-TExt Representation Learning
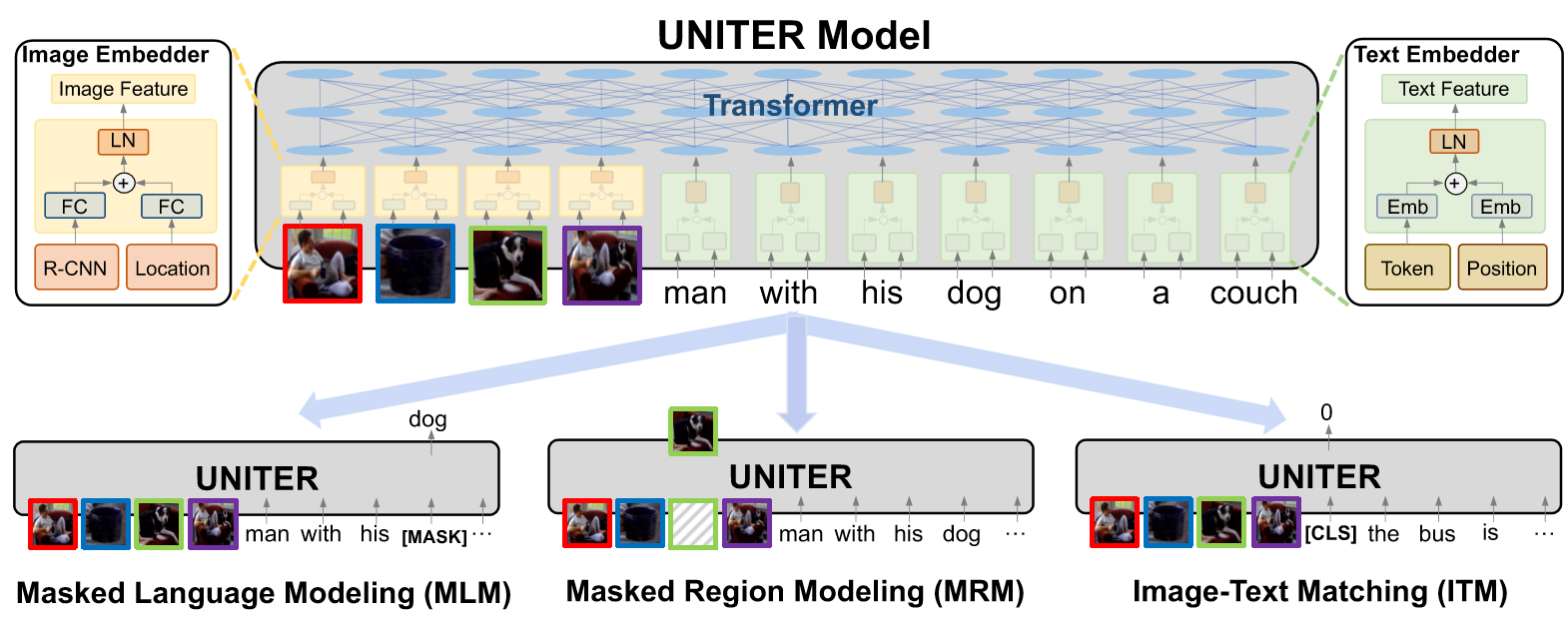
Joint image-text embedding is the bedrock for most Vision-and-Language (V+L) tasks, where multimodality inputs are simultaneously processed for joint visual and textual understanding. In this paper, we introduce UNITER, a UNiversal Image-TExt Representation, learned through large-scale pre-training over four image-text datasets (COCO, Visual Genome, Conceptual Captions, and SBU Captions), which can power heterogeneous downstream V+L tasks with joint multimodal embeddings. We design four pre-training tasks: Masked Language Modeling (MLM), Masked Region Modeling (MRM, with three variants), Image-Text Matching (ITM), and Word-Region Alignment (WRA). Different from previous work that applies joint random masking to both modalities, we use conditional masking on pre-training tasks (i.e., masked language/region modeling is conditioned on full observation of image/text). In addition to ITM for global image-text alignment, we also propose WRA via the use of Optimal Transport (OT) to explicitly encourage fine-grained alignment between words and image regions during pre-training. Comprehensive analysis shows that both conditional masking and OT-based WRA contribute to better pre-training. We also conduct a thorough ablation study to find an optimal combination of pre-training tasks. Extensive experiments show that UNITER achieves new state of the art across six V+L tasks (over nine datasets), including Visual Question Answering, Image-Text Retrieval, Referring Expression Comprehension, Visual Commonsense Reasoning, Visual Entailment, and NLVR$^2$. Code is available at https://github.com/ChenRocks/UNITER.
PDF Abstract ECCV 2020 PDF ECCV 2020 AbstractCode

Tasks
 Image-text matching
Image-text matching
 Language Modelling
Masked Language Modeling
Language Modelling
Masked Language Modeling
 Question Answering
Referring Expression
Referring Expression Comprehension
Question Answering
Referring Expression
Referring Expression Comprehension
 Representation Learning
Retrieval
Text Matching
Text Retrieval
Representation Learning
Retrieval
Text Matching
Text Retrieval
 Visual Commonsense Reasoning
Visual Commonsense Reasoning
 Visual Entailment
Visual Question Answering
Visual Entailment
Visual Question Answering
 Visual Question Answering (VQA)
Visual Reasoning
Zero-Shot Cross-Modal Retrieval
Visual Question Answering (VQA)
Visual Reasoning
Zero-Shot Cross-Modal Retrieval
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
 Flickr30k
Flickr30k
 Visual Question Answering v2.0
Visual Question Answering v2.0
 Conceptual Captions
Conceptual Captions
 RefCOCO
RefCOCO
 VCR
VCR
 NLVR
NLVR

