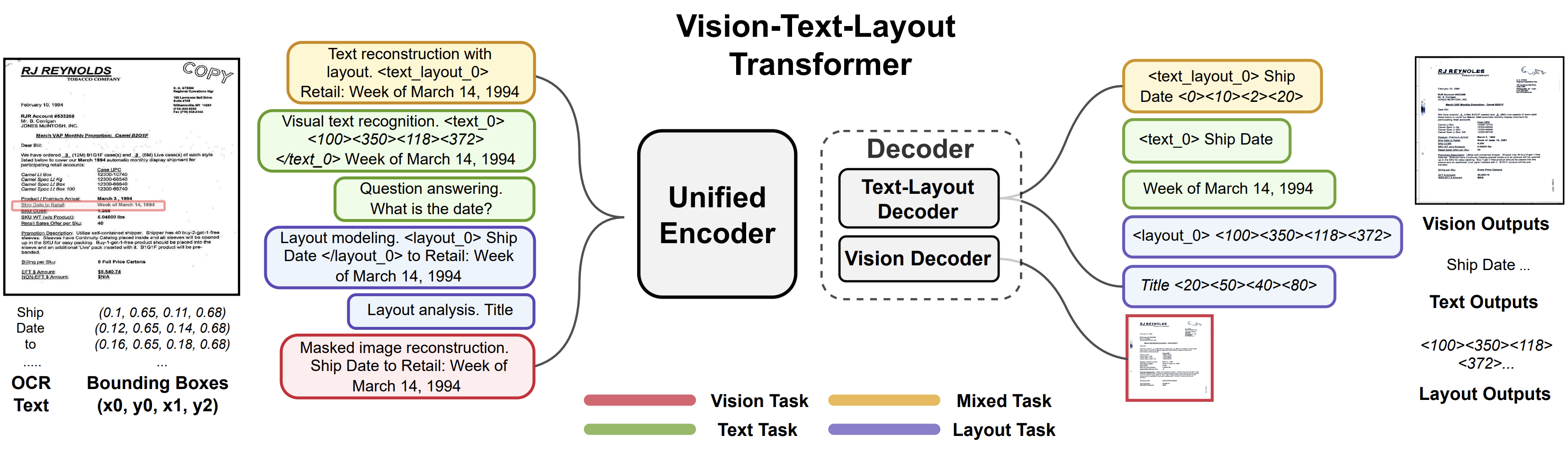
Unifying Vision, Text, and Layout for Universal Document Processing
We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 8 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark.
PDF Abstract CVPR 2023 PDF CVPR 2023 AbstractCode



 FUNSD
FUNSD
 RVL-CDIP
RVL-CDIP
 TabFact
TabFact
 InfographicVQA
InfographicVQA
Results from the Paper
 Ranked #5 on
Visual Question Answering (VQA)
on InfographicVQA
(using extra training data)
Ranked #5 on
Visual Question Answering (VQA)
on InfographicVQA
(using extra training data)
