Unifying Two-Stream Encoders with Transformers for Cross-Modal Retrieval
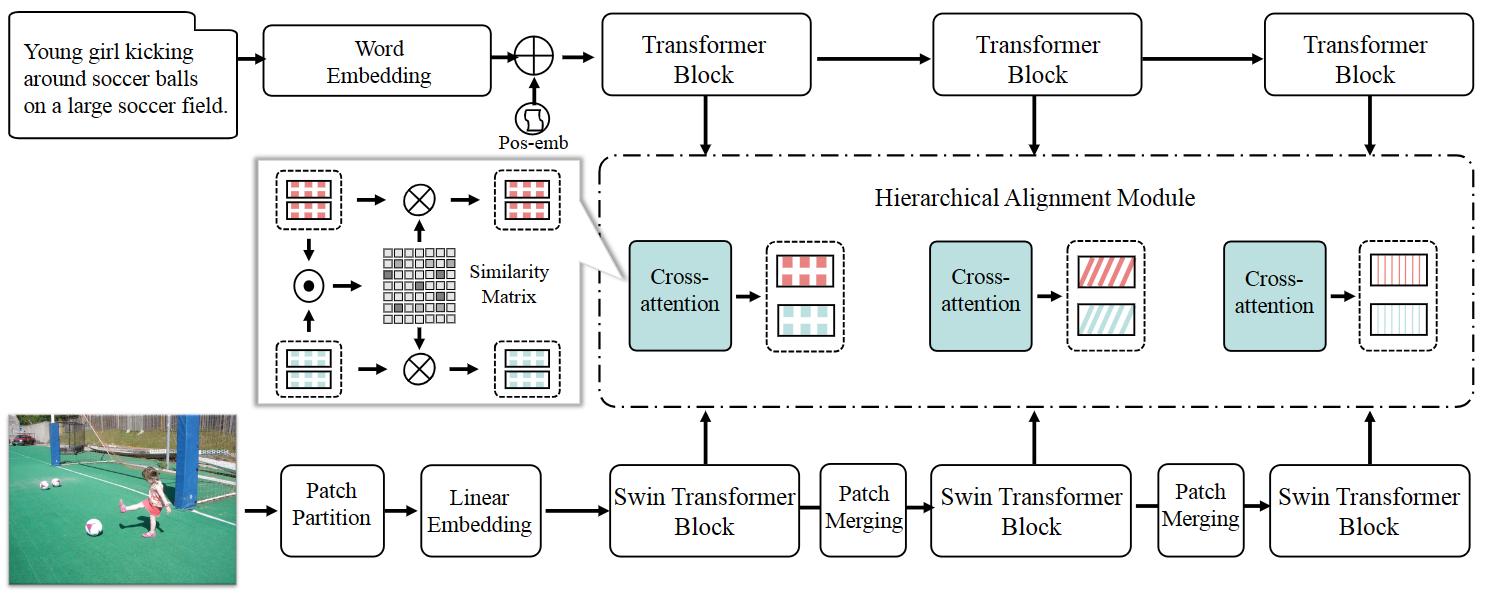
Most existing cross-modal retrieval methods employ two-stream encoders with different architectures for images and texts, \textit{e.g.}, CNN for images and RNN/Transformer for texts. Such discrepancy in architectures may induce different semantic distribution spaces and limit the interactions between images and texts, and further result in inferior alignment between images and texts. To fill this research gap, inspired by recent advances of Transformers in vision tasks, we propose to unify the encoder architectures with Transformers for both modalities. Specifically, we design a cross-modal retrieval framework purely based on two-stream Transformers, dubbed \textbf{Hierarchical Alignment Transformers (HAT)}, which consists of an image Transformer, a text Transformer, and a hierarchical alignment module. With such identical architectures, the encoders could produce representations with more similar characteristics for images and texts, and make the interactions and alignments between them much easier. Besides, to leverage the rich semantics, we devise a hierarchical alignment scheme to explore multi-level correspondences of different layers between images and texts. To evaluate the effectiveness of the proposed HAT, we conduct extensive experiments on two benchmark datasets, MSCOCO and Flickr30K. Experimental results demonstrate that HAT outperforms SOTA baselines by a large margin. Specifically, on two key tasks, \textit{i.e.}, image-to-text and text-to-image retrieval, HAT achieves 7.6\% and 16.7\% relative score improvement of Recall@1 on MSCOCO, and 4.4\% and 11.6\% on Flickr30k respectively. The code is available at \url{https://github.com/LuminosityX/HAT}.
PDF Abstract


 Flickr30k
Flickr30k
