UniFormer: Unifying Convolution and Self-attention for Visual Recognition
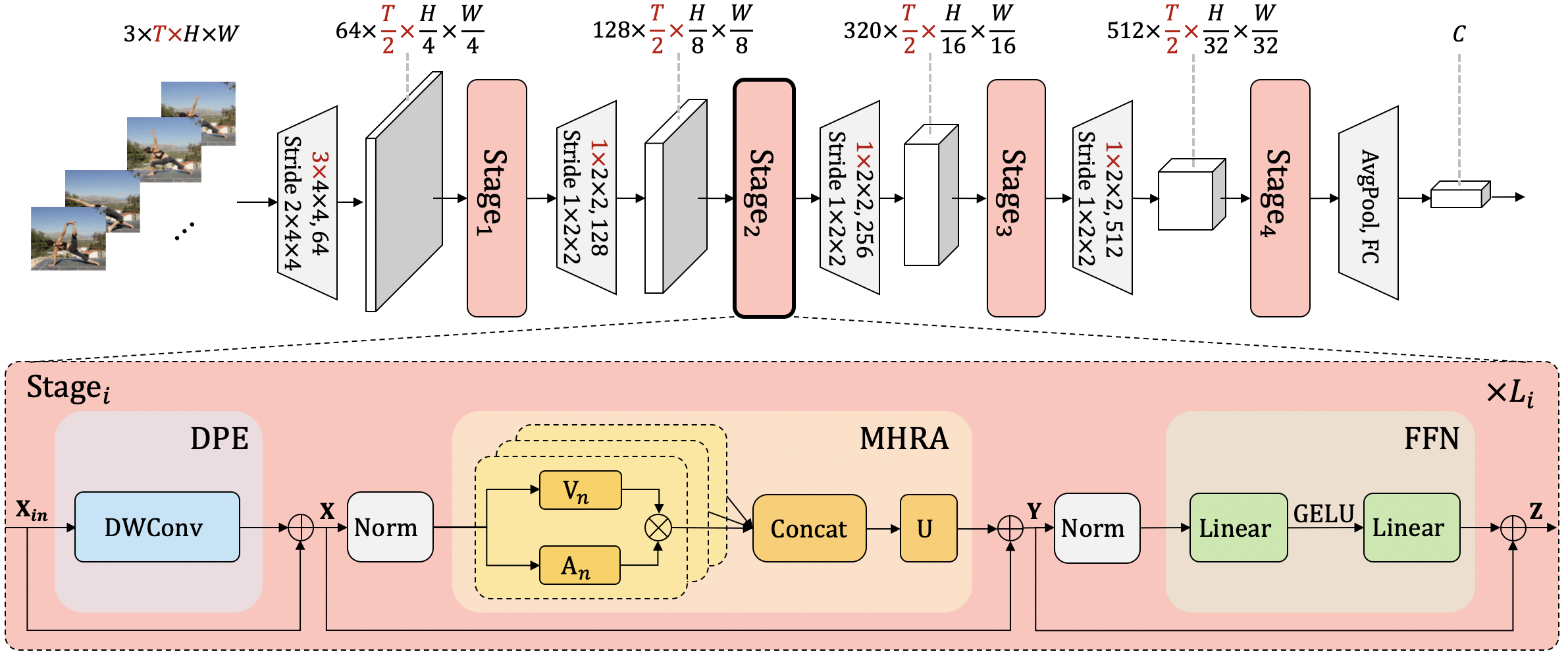
It is a challenging task to learn discriminative representation from images and videos, due to large local redundancy and complex global dependency in these visual data. Convolution neural networks (CNNs) and vision transformers (ViTs) have been two dominant frameworks in the past few years. Though CNNs can efficiently decrease local redundancy by convolution within a small neighborhood, the limited receptive field makes it hard to capture global dependency. Alternatively, ViTs can effectively capture long-range dependency via self-attention, while blind similarity comparisons among all the tokens lead to high redundancy. To resolve these problems, we propose a novel Unified transFormer (UniFormer), which can seamlessly integrate the merits of convolution and self-attention in a concise transformer format. Different from the typical transformer blocks, the relation aggregators in our UniFormer block are equipped with local and global token affinity respectively in shallow and deep layers, allowing to tackle both redundancy and dependency for efficient and effective representation learning. Finally, we flexibly stack our UniFormer blocks into a new powerful backbone, and adopt it for various vision tasks from image to video domain, from classification to dense prediction. Without any extra training data, our UniFormer achieves 86.3 top-1 accuracy on ImageNet-1K classification. With only ImageNet-1K pre-training, it can simply achieve state-of-the-art performance in a broad range of downstream tasks, e.g., it obtains 82.9/84.8 top-1 accuracy on Kinetics-400/600, 60.9/71.2 top-1 accuracy on Sth-Sth V1/V2 video classification, 53.8 box AP and 46.4 mask AP on COCO object detection, 50.8 mIoU on ADE20K semantic segmentation, and 77.4 AP on COCO pose estimation. We further build an efficient UniFormer with 2-4x higher throughput. Code is available at https://github.com/Sense-X/UniFormer.
PDF Abstract Spaces
Spaces

 Colab
Colab







 ImageNet
ImageNet
 MS COCO
MS COCO
 UCF101
UCF101
 Something-Something V2
Something-Something V2
 Kinetics-600
Kinetics-600
 Something-Something V1
Something-Something V1

