UnifiedGesture: A Unified Gesture Synthesis Model for Multiple Skeletons
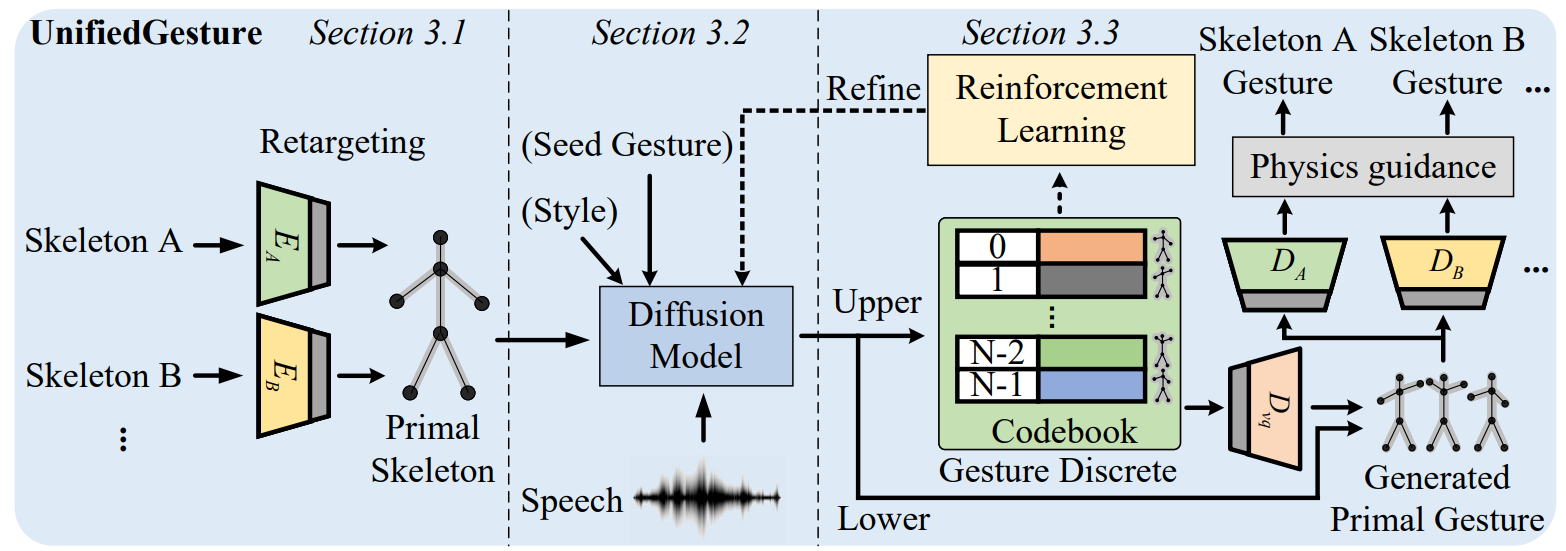
The automatic co-speech gesture generation draws much attention in computer animation. Previous works designed network structures on individual datasets, which resulted in a lack of data volume and generalizability across different motion capture standards. In addition, it is a challenging task due to the weak correlation between speech and gestures. To address these problems, we present UnifiedGesture, a novel diffusion model-based speech-driven gesture synthesis approach, trained on multiple gesture datasets with different skeletons. Specifically, we first present a retargeting network to learn latent homeomorphic graphs for different motion capture standards, unifying the representations of various gestures while extending the dataset. We then capture the correlation between speech and gestures based on a diffusion model architecture using cross-local attention and self-attention to generate better speech-matched and realistic gestures. To further align speech and gesture and increase diversity, we incorporate reinforcement learning on the discrete gesture units with a learned reward function. Extensive experiments show that UnifiedGesture outperforms recent approaches on speech-driven gesture generation in terms of CCA, FGD, and human-likeness. All code, pre-trained models, databases, and demos are available to the public at https://github.com/YoungSeng/UnifiedGesture.
PDF Abstract

