Unified Multi-modal Unsupervised Representation Learning for Skeleton-based Action Understanding
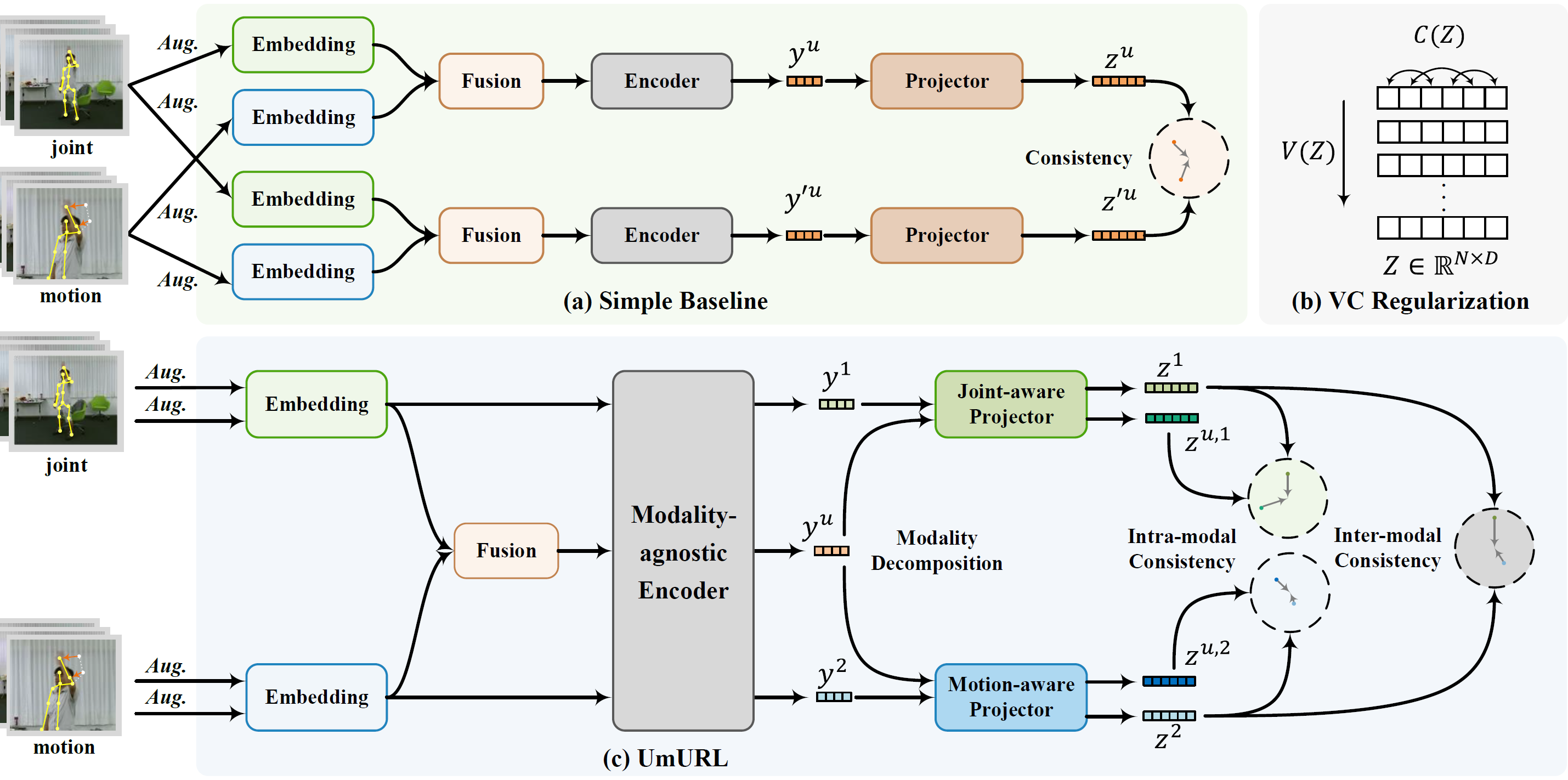
Unsupervised pre-training has shown great success in skeleton-based action understanding recently. Existing works typically train separate modality-specific models, then integrate the multi-modal information for action understanding by a late-fusion strategy. Although these approaches have achieved significant performance, they suffer from the complex yet redundant multi-stream model designs, each of which is also limited to the fixed input skeleton modality. To alleviate these issues, in this paper, we propose a Unified Multimodal Unsupervised Representation Learning framework, called UmURL, which exploits an efficient early-fusion strategy to jointly encode the multi-modal features in a single-stream manner. Specifically, instead of designing separate modality-specific optimization processes for uni-modal unsupervised learning, we feed different modality inputs into the same stream with an early-fusion strategy to learn their multi-modal features for reducing model complexity. To ensure that the fused multi-modal features do not exhibit modality bias, i.e., being dominated by a certain modality input, we further propose both intra- and inter-modal consistency learning to guarantee that the multi-modal features contain the complete semantics of each modal via feature decomposition and distinct alignment. In this manner, our framework is able to learn the unified representations of uni-modal or multi-modal skeleton input, which is flexible to different kinds of modality input for robust action understanding in practical cases. Extensive experiments conducted on three large-scale datasets, i.e., NTU-60, NTU-120, and PKU-MMD II, demonstrate that UmURL is highly efficient, possessing the approximate complexity with the uni-modal methods, while achieving new state-of-the-art performance across various downstream task scenarios in skeleton-based action representation learning.
PDF Abstract


