Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark
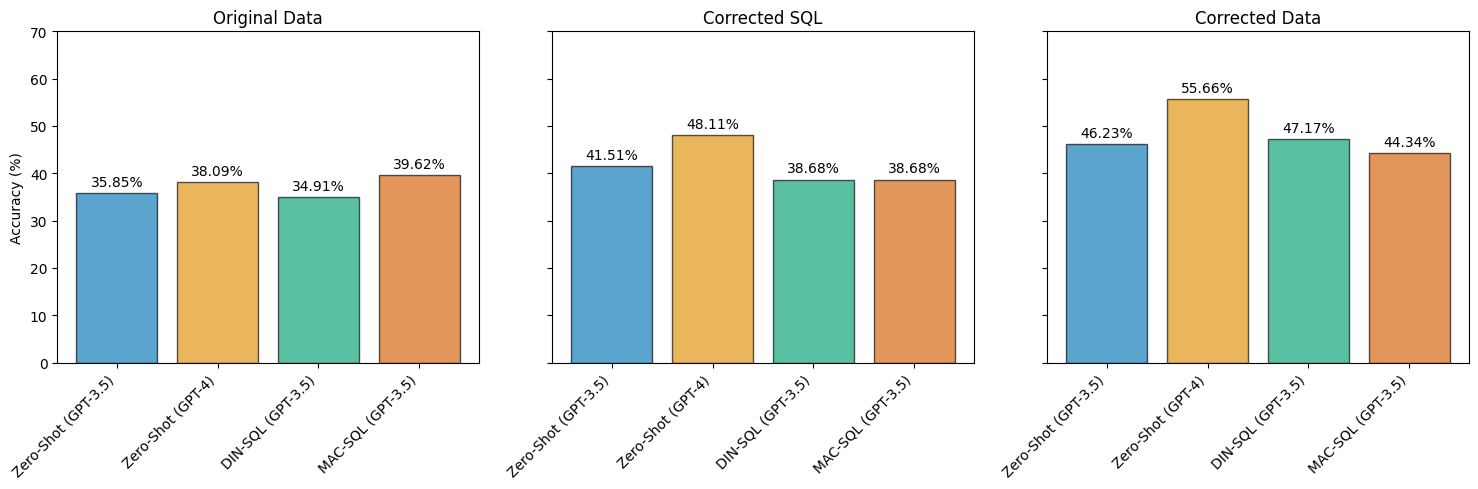
Text-to-SQL, which involves translating natural language into Structured Query Language (SQL), is crucial for enabling broad access to structured databases without expert knowledge. However, designing models for such tasks is challenging due to numerous factors, including the presence of 'noise,' such as ambiguous questions and syntactical errors. This study provides an in-depth analysis of the distribution and types of noise in the widely used BIRD-Bench benchmark and the impact of noise on models. While BIRD-Bench was created to model dirty and noisy database values, it was not created to contain noise and errors in the questions and gold queries. We found that noise in questions and gold queries are prevalent in the dataset, with varying amounts across domains, and with an uneven distribution between noise types. The presence of incorrect gold SQL queries, which then generate incorrect gold answers, has a significant impact on the benchmark's reliability. Surprisingly, when evaluating models on corrected SQL queries, zero-shot baselines surpassed the performance of state-of-the-art prompting methods. We conclude that informative noise labels and reliable benchmarks are crucial to developing new Text-to-SQL methods that can handle varying types of noise. All datasets, annotations, and code are available at https://github.com/niklaswretblad/the-effects-of-noise-in-text-to-SQL.
PDF Abstract
 WikiSQL
WikiSQL
