Understanding and Improving Feature Learning for Out-of-Distribution Generalization
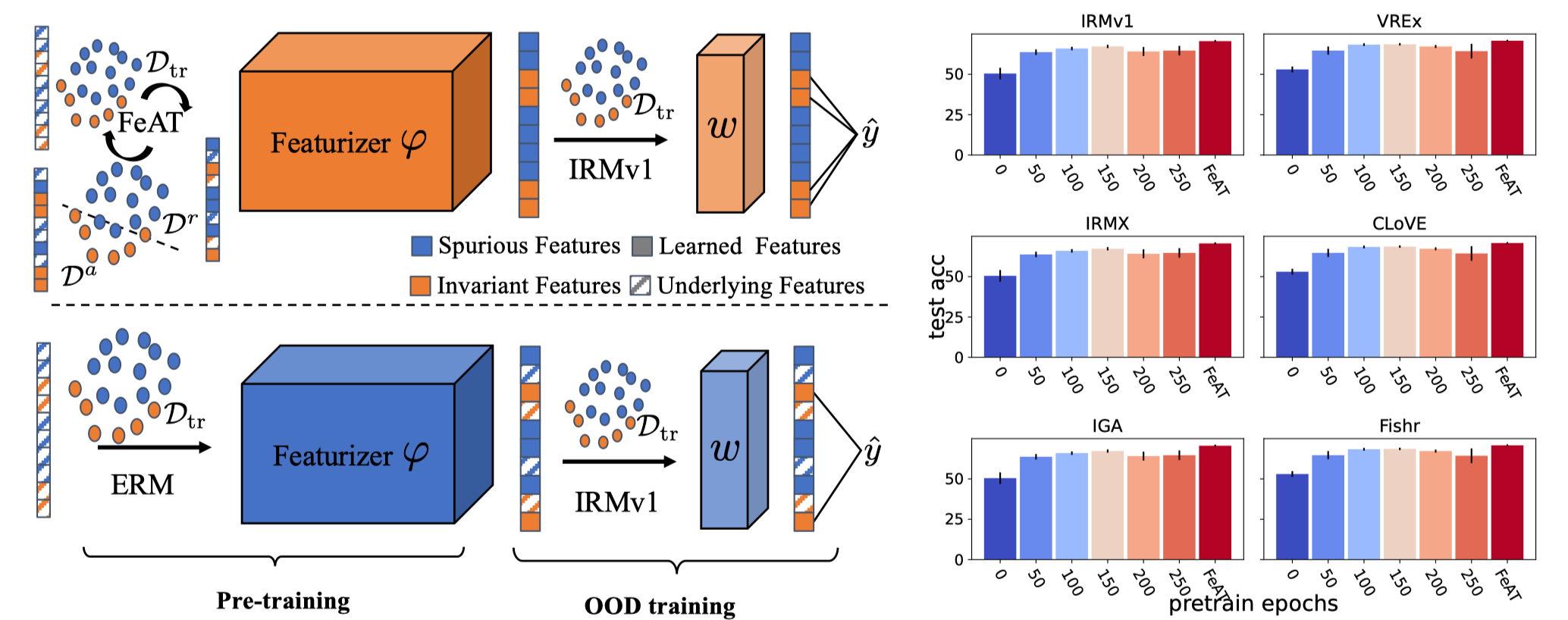
A common explanation for the failure of out-of-distribution (OOD) generalization is that the model trained with empirical risk minimization (ERM) learns spurious features instead of invariant features. However, several recent studies challenged this explanation and found that deep networks may have already learned sufficiently good features for OOD generalization. Despite the contradictions at first glance, we theoretically show that ERM essentially learns both spurious and invariant features, while ERM tends to learn spurious features faster if the spurious correlation is stronger. Moreover, when fed the ERM learned features to the OOD objectives, the invariant feature learning quality significantly affects the final OOD performance, as OOD objectives rarely learn new features. Therefore, ERM feature learning can be a bottleneck to OOD generalization. To alleviate the reliance, we propose Feature Augmented Training (FeAT), to enforce the model to learn richer features ready for OOD generalization. FeAT iteratively augments the model to learn new features while retaining the already learned features. In each round, the retention and augmentation operations are performed on different subsets of the training data that capture distinct features. Extensive experiments show that FeAT effectively learns richer features thus boosting the performance of various OOD objectives.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract

