Understanding Adversarial Robustness of Vision Transformers via Cauchy Problem
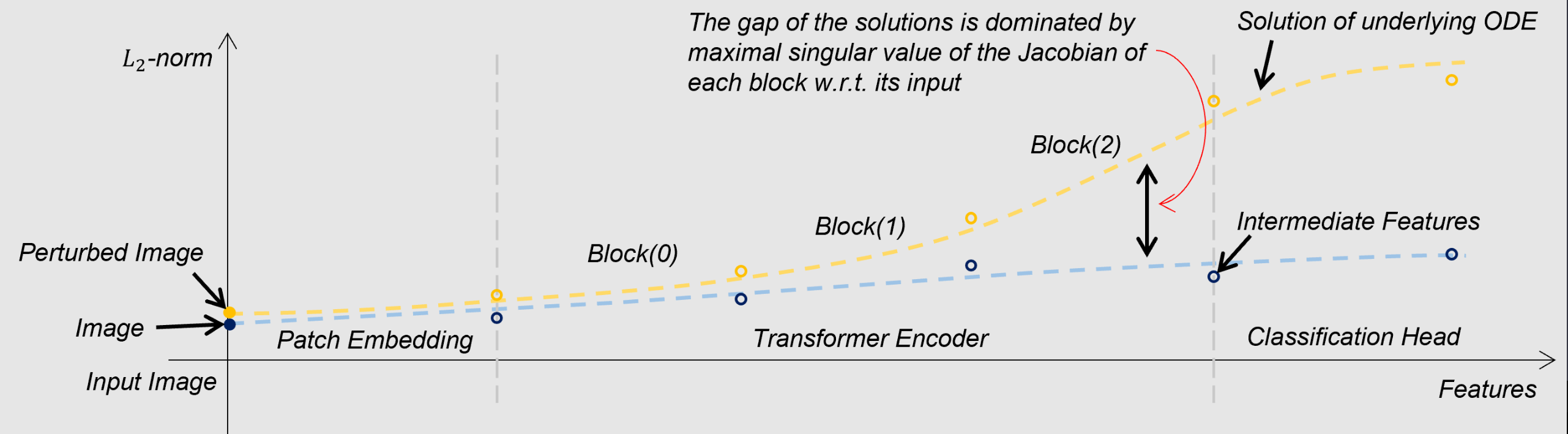
Recent research on the robustness of deep learning has shown that Vision Transformers (ViTs) surpass the Convolutional Neural Networks (CNNs) under some perturbations, e.g., natural corruption, adversarial attacks, etc. Some papers argue that the superior robustness of ViT comes from the segmentation of its input images; others say that the Multi-head Self-Attention (MSA) is the key to preserving the robustness. In this paper, we aim to introduce a principled and unified theoretical framework to investigate such an argument on ViT's robustness. We first theoretically prove that, unlike Transformers in Natural Language Processing, ViTs are Lipschitz continuous. Then we theoretically analyze the adversarial robustness of ViTs from the perspective of the Cauchy Problem, via which we can quantify how the robustness propagates through layers. We demonstrate that the first and last layers are the critical factors to affect the robustness of ViTs. Furthermore, based on our theory, we empirically show that unlike the claims from existing research, MSA only contributes to the adversarial robustness of ViTs under weak adversarial attacks, e.g., FGSM, and surprisingly, MSA actually comprises the model's adversarial robustness under stronger attacks, e.g., PGD attacks.
PDF Abstract

