TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation
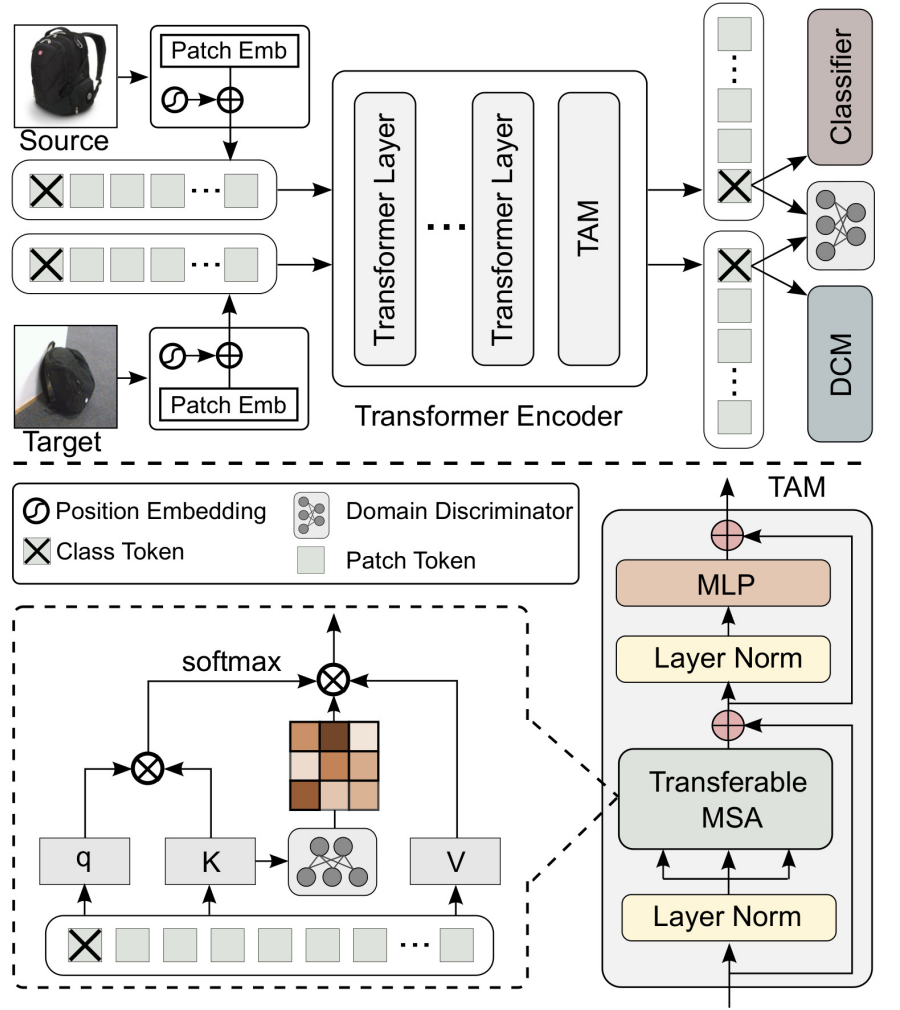
Unsupervised domain adaptation (UDA) aims to transfer the knowledge learnt from a labeled source domain to an unlabeled target domain. Previous work is mainly built upon convolutional neural networks (CNNs) to learn domain-invariant representations. With the recent exponential increase in applying Vision Transformer (ViT) to vision tasks, the capability of ViT in adapting cross-domain knowledge, however, remains unexplored in the literature. To fill this gap, this paper first comprehensively investigates the transferability of ViT on a variety of domain adaptation tasks. Surprisingly, ViT demonstrates superior transferability over its CNNs-based counterparts with a large margin, while the performance can be further improved by incorporating adversarial adaptation. Notwithstanding, directly using CNNs-based adaptation strategies fails to take the advantage of ViT's intrinsic merits (e.g., attention mechanism and sequential image representation) which play an important role in knowledge transfer. To remedy this, we propose an unified framework, namely Transferable Vision Transformer (TVT), to fully exploit the transferability of ViT for domain adaptation. Specifically, we delicately devise a novel and effective unit, which we term Transferability Adaption Module (TAM). By injecting learned transferabilities into attention blocks, TAM compels ViT focus on both transferable and discriminative features. Besides, we leverage discriminative clustering to enhance feature diversity and separation which are undermined during adversarial domain alignment. To verify its versatility, we perform extensive studies of TVT on four benchmarks and the experimental results demonstrate that TVT attains significant improvements compared to existing state-of-the-art UDA methods.
PDF Abstract



 MNIST
MNIST
 SVHN
SVHN
 Office-Home
Office-Home
 Office-31
Office-31
 VisDA-2017
VisDA-2017
