TTD: Text-Tag Self-Distillation Enhancing Image-Text Alignment in CLIP to Alleviate Single Tag Bias
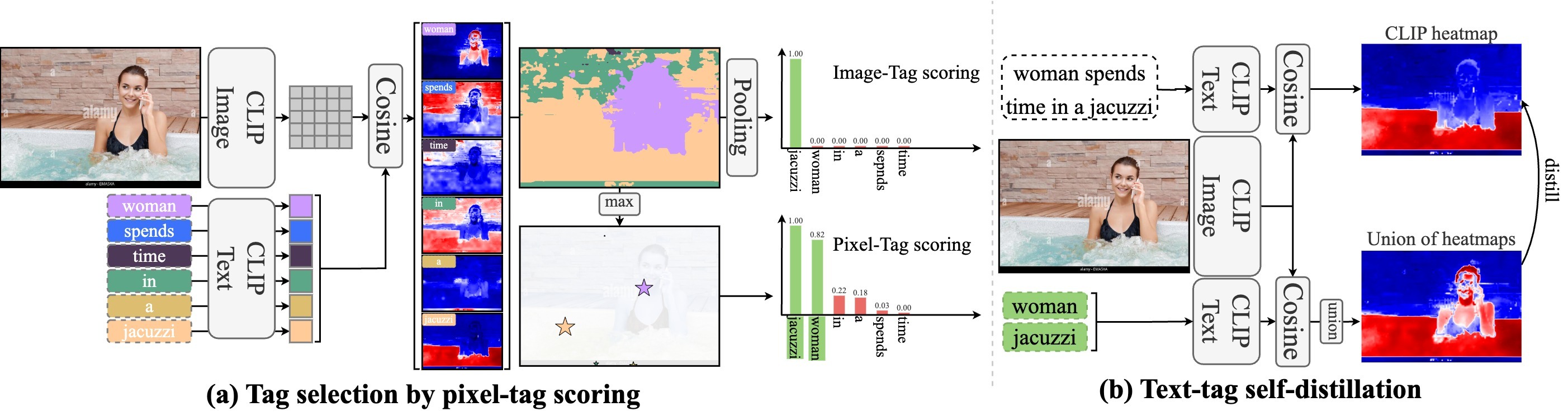
We identify a critical bias in contemporary CLIP-based models, which we denote as \textit{single tag bias}. This bias manifests as a disproportionate focus on a singular tag (word) while neglecting other pertinent tags, stemming from CLIP's text embeddings that prioritize one specific tag in image-text relationships. When deconstructing text into individual tags, only one tag tends to have high relevancy with CLIP's image embedding, leading to an imbalanced tag relevancy. This results in an uneven alignment among multiple tags present in the text. To tackle this challenge, we introduce a novel two-step fine-tuning approach. First, our method leverages the similarity between tags and their nearest pixels for scoring, enabling the extraction of image-relevant tags from the text. Second, we present a self-distillation strategy aimed at aligning the combined masks from extracted tags with the text-derived mask. This approach mitigates the single tag bias, thereby significantly improving the alignment of CLIP's model without necessitating additional data or supervision. Our technique demonstrates model-agnostic improvements in multi-tag classification and segmentation tasks, surpassing competing methods that rely on external resources. Code is available at https://github.com/shjo-april/TTD.
PDF AbstractCode


Datasets
Introduced in the Paper:
CC3M-TagMaskUsed in the Paper:
 Cityscapes
Cityscapes
 ADE20K
ADE20K
 PASCAL Context
PASCAL Context
 COCO-Stuff
COCO-Stuff
 PASCAL VOC
PASCAL VOC
Results from the Paper
 Ranked #1 on
Open Vocabulary Semantic Segmentation
on COCO-Stuff-171
(mIoU metric)
Ranked #1 on
Open Vocabulary Semantic Segmentation
on COCO-Stuff-171
(mIoU metric)
