Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
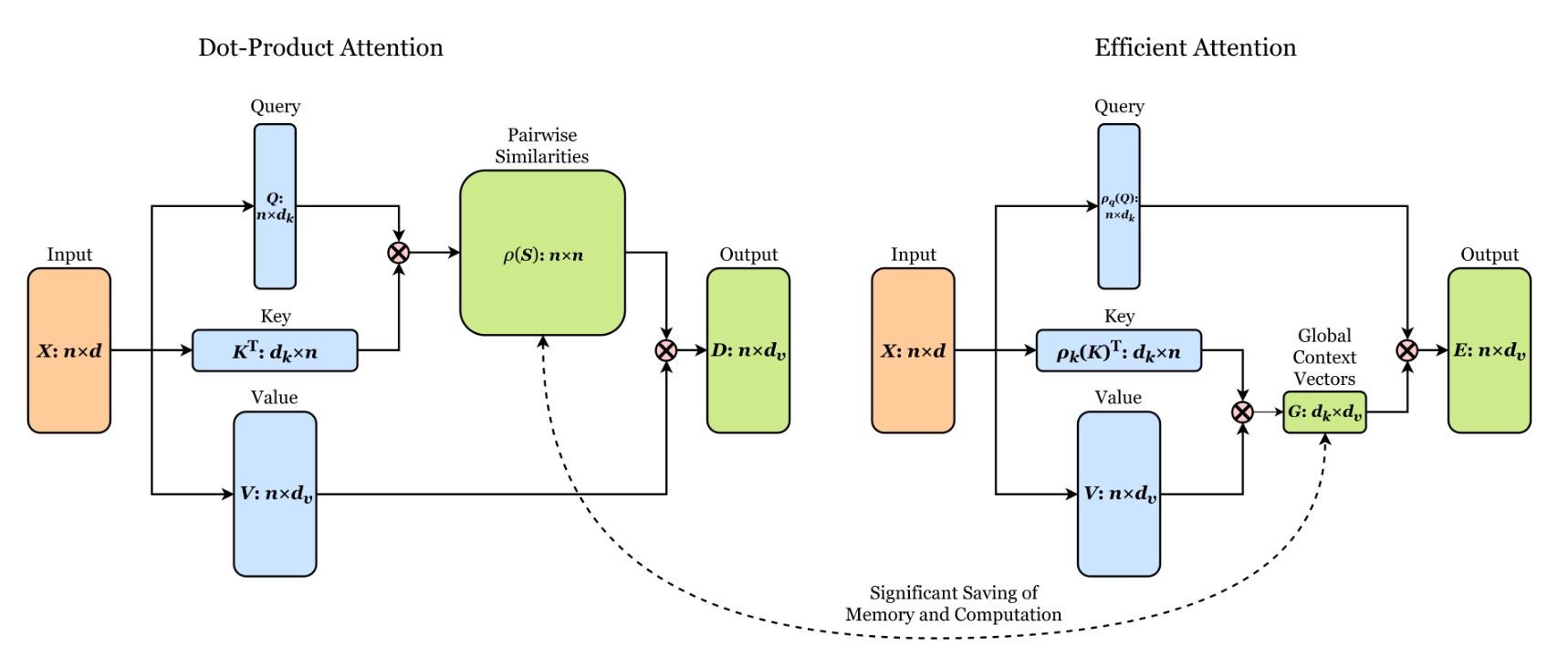
Transformers achieve remarkable performance in several tasks but due to their quadratic complexity, with respect to the input's length, they are prohibitively slow for very long sequences. To address this limitation, we express the self-attention as a linear dot-product of kernel feature maps and make use of the associativity property of matrix products to reduce the complexity from $\mathcal{O}\left(N^2\right)$ to $\mathcal{O}\left(N\right)$, where $N$ is the sequence length. We show that this formulation permits an iterative implementation that dramatically accelerates autoregressive transformers and reveals their relationship to recurrent neural networks. Our linear transformers achieve similar performance to vanilla transformers and they are up to 4000x faster on autoregressive prediction of very long sequences.
PDF Abstract ICML 2020 PDF



 CIFAR-10
CIFAR-10
 WikiText-2
WikiText-2
 WikiText-103
WikiText-103
 D4RL
D4RL

