Stabilize Deep ResNet with A Sharp Scaling Factor $τ$
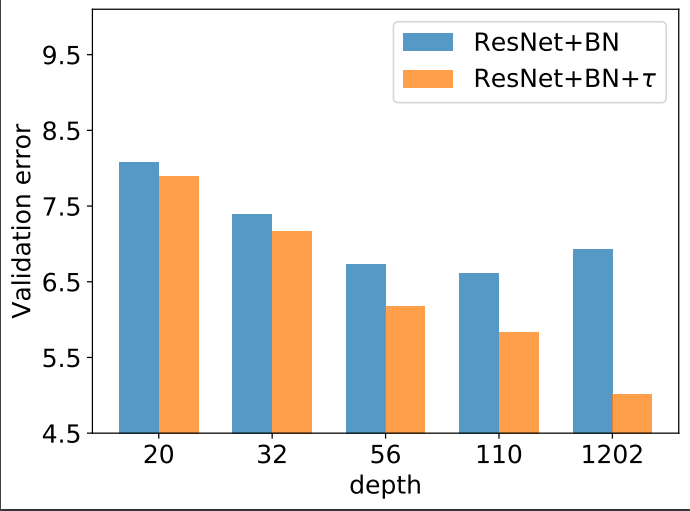
We study the stability and convergence of training deep ResNets with gradient descent. Specifically, we show that the parametric branch in the residual block should be scaled down by a factor $\tau =O(1/\sqrt{L})$ to guarantee stable forward/backward process, where $L$ is the number of residual blocks. Moreover, we establish a converse result that the forward process is unbounded when $\tau>L^{-\frac{1}{2}+c}$, for any positive constant $c$. The above two results together establish a sharp value of the scaling factor in determining the stability of deep ResNet. Based on the stability result, we further show that gradient descent finds the global minima if the ResNet is properly over-parameterized, which significantly improves over the previous work with a much larger range of $\tau$ that admits global convergence. Moreover, we show that the convergence rate is independent of the depth, theoretically justifying the advantage of ResNet over vanilla feedforward network. Empirically, with such a factor $\tau$, one can train deep ResNet without normalization layer. Moreover, for ResNets with normalization layer, adding such a factor $\tau$ also stabilizes the training and obtains significant performance gain for deep ResNet.
PDF Abstract
 CIFAR-10
CIFAR-10
 MNIST
MNIST
