Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision
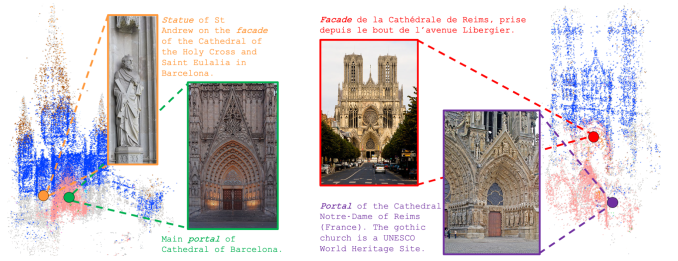
The abundance and richness of Internet photos of landmarks and cities has led to significant progress in 3D vision over the past two decades, including automated 3D reconstructions of the world's landmarks from tourist photos. However, a major source of information available for these 3D-augmented collections---namely language, e.g., from image captions---has been virtually untapped. In this work, we present WikiScenes, a new, large-scale dataset of landmark photo collections that contains descriptive text in the form of captions and hierarchical category names. WikiScenes forms a new testbed for multimodal reasoning involving images, text, and 3D geometry. We demonstrate the utility of WikiScenes for learning semantic concepts over images and 3D models. Our weakly-supervised framework connects images, 3D structure, and semantics---utilizing the strong constraints provided by 3D geometry---to associate semantic concepts to image pixels and 3D points.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract


 WikiScenes
WikiScenes
 ShapeNet
ShapeNet
 Visual Question Answering
Visual Question Answering
