Towards Viewpoint-Invariant Visual Recognition via Adversarial Training
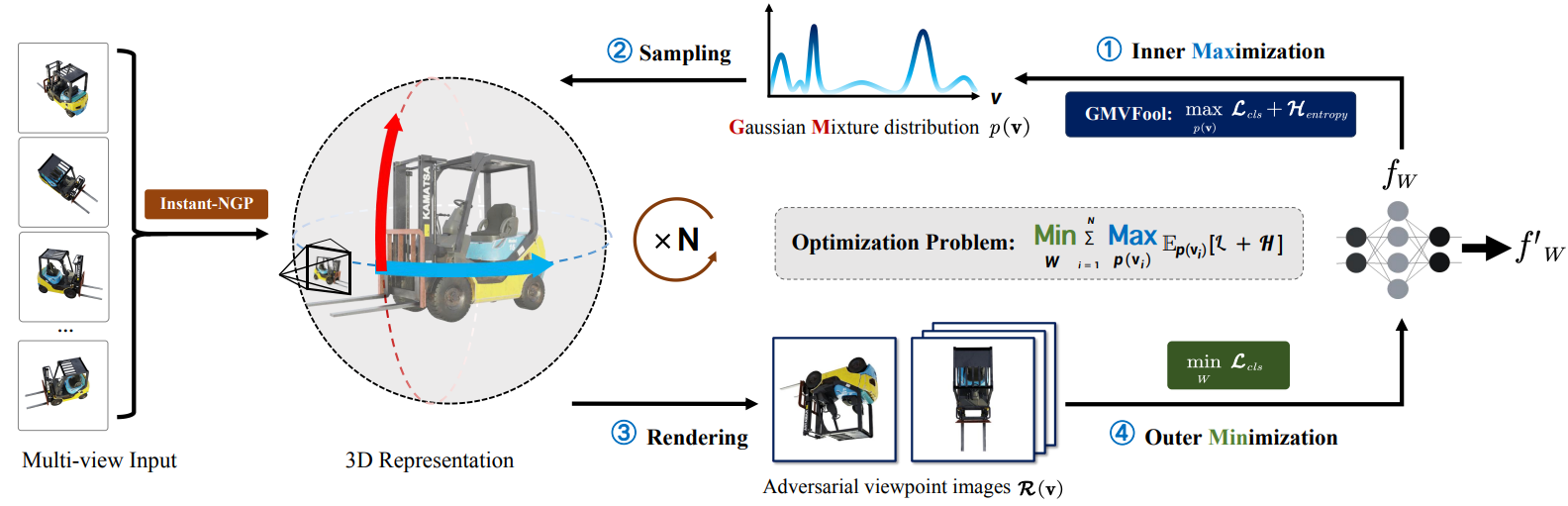
Visual recognition models are not invariant to viewpoint changes in the 3D world, as different viewing directions can dramatically affect the predictions given the same object. Although many efforts have been devoted to making neural networks invariant to 2D image translations and rotations, viewpoint invariance is rarely investigated. As most models process images in the perspective view, it is challenging to impose invariance to 3D viewpoint changes based only on 2D inputs. Motivated by the success of adversarial training in promoting model robustness, we propose Viewpoint-Invariant Adversarial Training (VIAT) to improve viewpoint robustness of common image classifiers. By regarding viewpoint transformation as an attack, VIAT is formulated as a minimax optimization problem, where the inner maximization characterizes diverse adversarial viewpoints by learning a Gaussian mixture distribution based on a new attack GMVFool, while the outer minimization trains a viewpoint-invariant classifier by minimizing the expected loss over the worst-case adversarial viewpoint distributions. To further improve the generalization performance, a distribution sharing strategy is introduced leveraging the transferability of adversarial viewpoints across objects. Experiments validate the effectiveness of VIAT in improving the viewpoint robustness of various image classifiers based on the diversity of adversarial viewpoints generated by GMVFool.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract
 ImageNet-R
ImageNet-R
 ObjectNet
ObjectNet
 Objectron
Objectron
