Towards Tracing Trustworthiness Dynamics: Revisiting Pre-training Period of Large Language Models
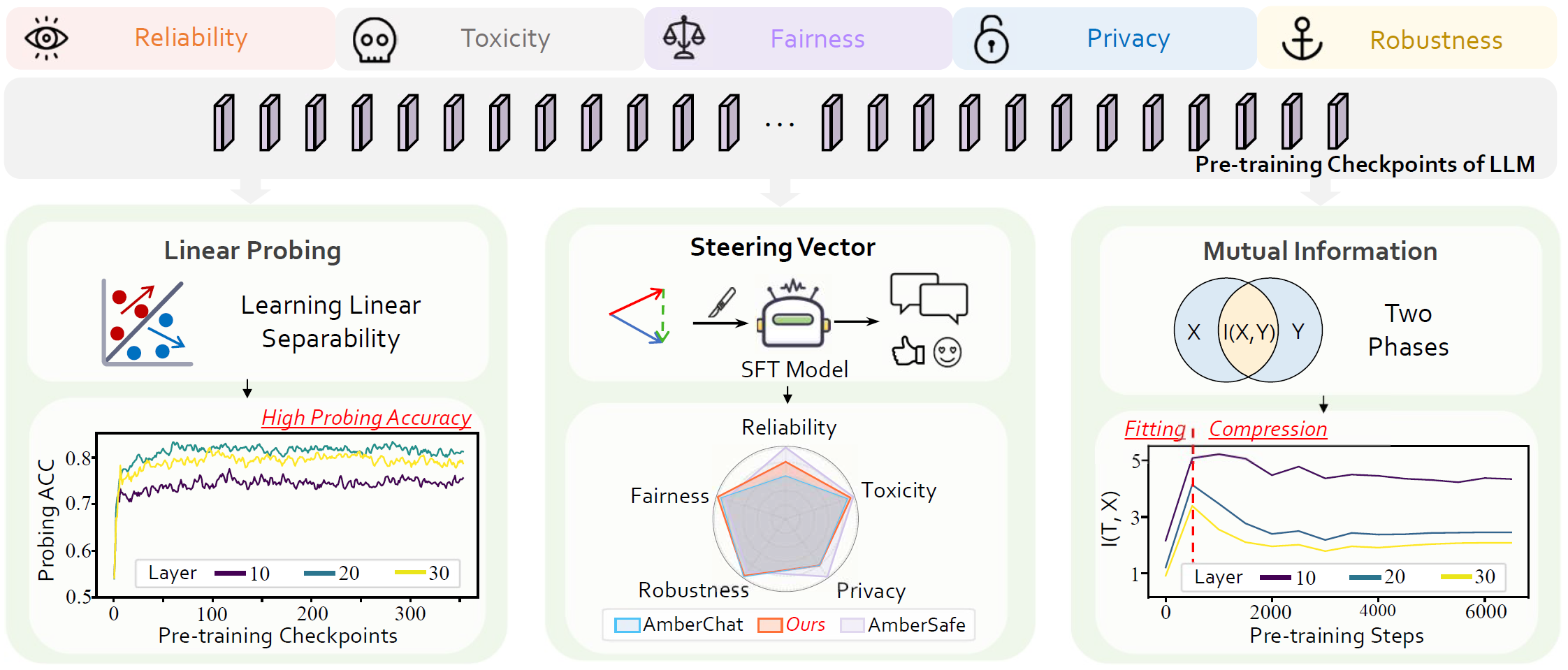
Ensuring the trustworthiness of large language models (LLMs) is crucial. Most studies concentrate on fully pre-trained LLMs to better understand and improve LLMs' trustworthiness. In this paper, to reveal the untapped potential of pre-training, we pioneer the exploration of LLMs' trustworthiness during this period, focusing on five key dimensions: reliability, privacy, toxicity, fairness, and robustness. To begin with, we apply linear probing to LLMs. The high probing accuracy suggests that \textit{LLMs in early pre-training can already distinguish concepts in each trustworthiness dimension}. Therefore, to further uncover the hidden possibilities of pre-training, we extract steering vectors from a LLM's pre-training checkpoints to enhance the LLM's trustworthiness. Finally, inspired by~\citet{choi2023understanding} that mutual information estimation is bounded by linear probing accuracy, we also probe LLMs with mutual information to investigate the dynamics of trustworthiness during pre-training. We are the first to observe a similar two-phase phenomenon: fitting and compression~\citep{shwartz2017opening}. This research provides an initial exploration of trustworthiness modeling during LLM pre-training, seeking to unveil new insights and spur further developments in the field. We will make our code publicly accessible at \url{https://github.com/ChnQ/TracingLLM}.
PDF Abstract
 GLUE
GLUE
 SST
SST
 TruthfulQA
TruthfulQA
