Towards Open-World Text-Guided Face Image Generation and Manipulation
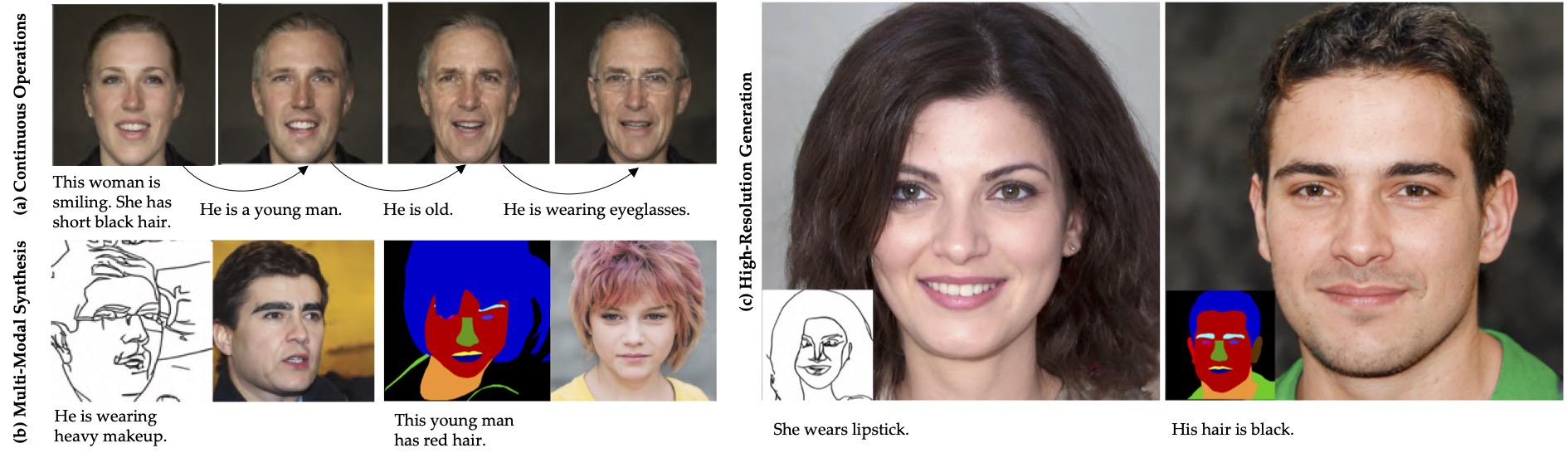
The existing text-guided image synthesis methods can only produce limited quality results with at most \mbox{$\text{256}^2$} resolution and the textual instructions are constrained in a small Corpus. In this work, we propose a unified framework for both face image generation and manipulation that produces diverse and high-quality images with an unprecedented resolution at 1024 from multimodal inputs. More importantly, our method supports open-world scenarios, including both image and text, without any re-training, fine-tuning, or post-processing. To be specific, we propose a brand new paradigm of text-guided image generation and manipulation based on the superior characteristics of a pretrained GAN model. Our proposed paradigm includes two novel strategies. The first strategy is to train a text encoder to obtain latent codes that align with the hierarchically semantic of the aforementioned pretrained GAN model. The second strategy is to directly optimize the latent codes in the latent space of the pretrained GAN model with guidance from a pretrained language model. The latent codes can be randomly sampled from a prior distribution or inverted from a given image, which provides inherent supports for both image generation and manipulation from multi-modal inputs, such as sketches or semantic labels, with textual guidance. To facilitate text-guided multi-modal synthesis, we propose the Multi-Modal CelebA-HQ, a large-scale dataset consisting of real face images and corresponding semantic segmentation map, sketch, and textual descriptions. Extensive experiments on the introduced dataset demonstrate the superior performance of our proposed method. Code and data are available at https://github.com/weihaox/TediGAN.
PDF Abstract Colab
Colab





 MS COCO
MS COCO
 CUB-200-2011
CUB-200-2011
 FFHQ
FFHQ
 CelebA-HQ
CelebA-HQ
 Multi-Modal CelebA-HQ
Multi-Modal CelebA-HQ

