Towards Boosting Many-to-Many Multilingual Machine Translation with Large Language Models
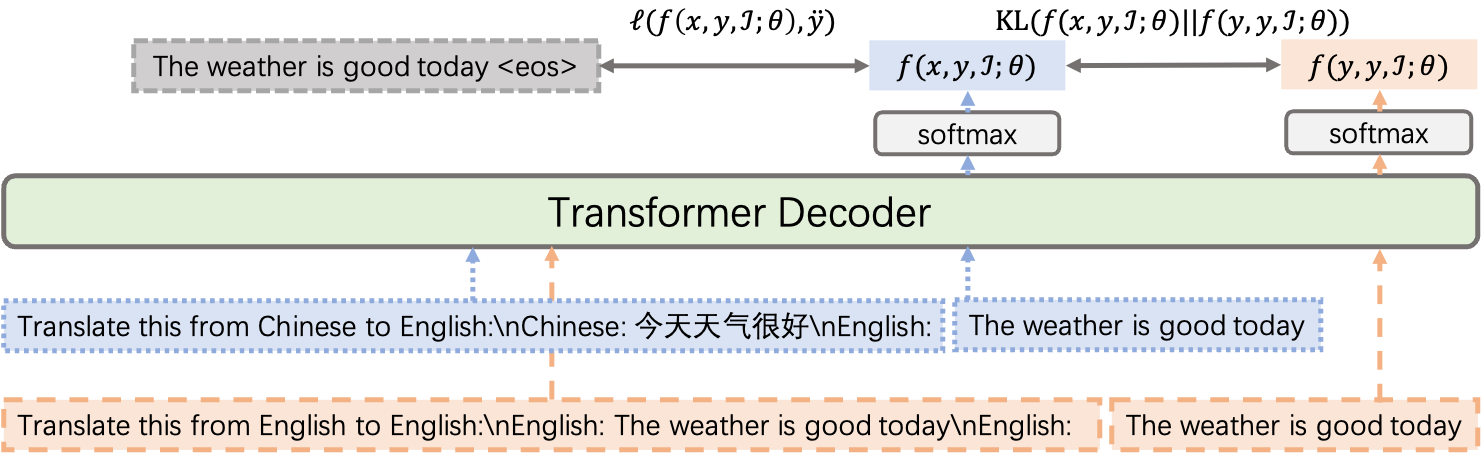
The training paradigm for machine translation has gradually shifted, from learning neural machine translation (NMT) models with extensive parallel corpora to instruction finetuning on multilingual large language models (LLMs) with high-quality translation pairs. In this paper, we focus on boosting many-to-many multilingual translation of LLMs with an emphasis on zero-shot translation directions. We demonstrate that prompt strategies adopted during finetuning are crucial to zero-shot translation and introduce a cross-lingual consistency regularization, XConST, to bridge the representation gap among different languages and improve zero-shot translation performance. XConST is not a new method, but a version of CrossConST (Gao et al., 2023a) adapted for translation instruction finetuning with LLMs. Experimental results on ALMA (Xu et al., 2023), Tower (Team, 2024), and LLaMA-2 (Touvron et al., 2023) show that our approach consistently improves translation performance. Our implementations are available at https://github.com/gpengzhi/CrossConST-LLM.
PDF Abstract


