Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing
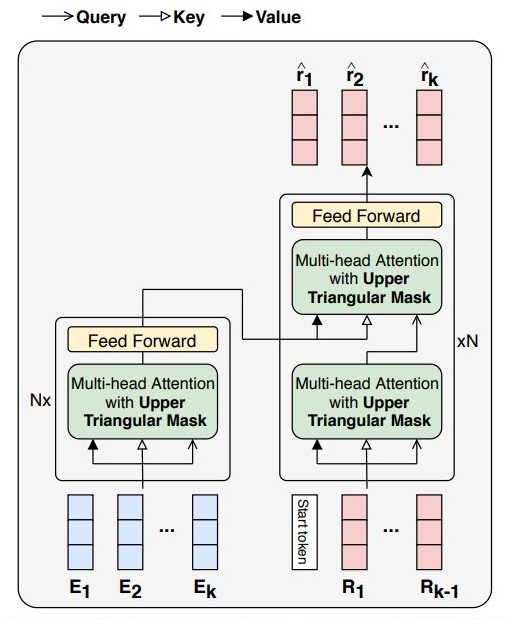
Knowledge tracing, the act of modeling a student's knowledge through learning activities, is an extensively studied problem in the field of computer-aided education. Although models with attention mechanism have outperformed traditional approaches such as Bayesian knowledge tracing and collaborative filtering, they share two limitations. Firstly, the models rely on shallow attention layers and fail to capture complex relations among exercises and responses over time. Secondly, different combinations of queries, keys and values for the self-attention layer for knowledge tracing were not extensively explored. Usual practice of using exercises and interactions (exercise-response pairs) as queries and keys/values respectively lacks empirical support. In this paper, we propose a novel Transformer based model for knowledge tracing, SAINT: Separated Self-AttentIve Neural Knowledge Tracing. SAINT has an encoder-decoder structure where exercise and response embedding sequence separately enter the encoder and the decoder respectively, which allows to stack attention layers multiple times. To the best of our knowledge, this is the first work to suggest an encoder-decoder model for knowledge tracing that applies deep self-attentive layers to exercises and responses separately. The empirical evaluations on a large-scale knowledge tracing dataset show that SAINT achieves the state-of-the-art performance in knowledge tracing with the improvement of AUC by 1.8% compared to the current state-of-the-art models.
PDF Abstract




