TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
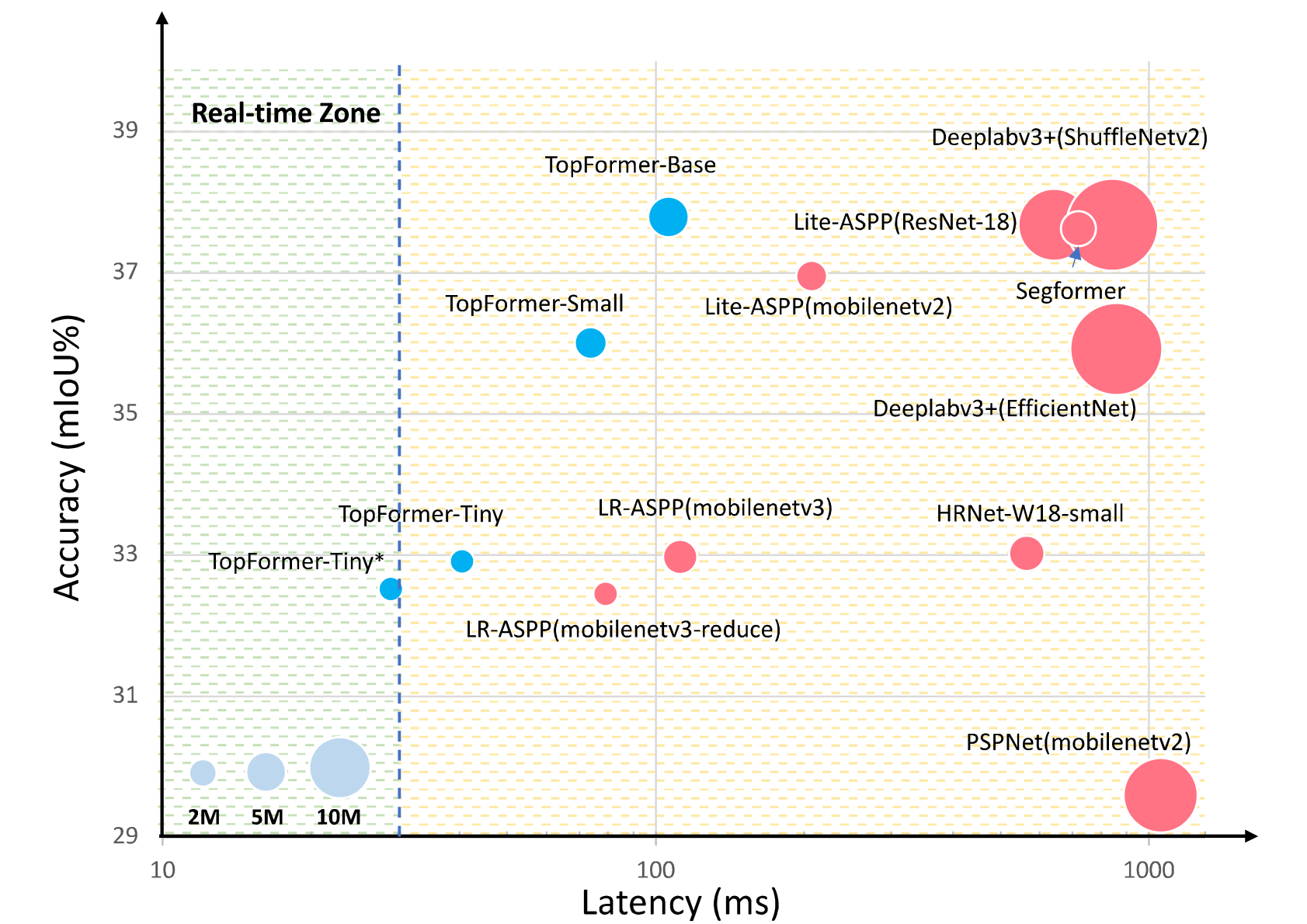
Although vision transformers (ViTs) have achieved great success in computer vision, the heavy computational cost hampers their applications to dense prediction tasks such as semantic segmentation on mobile devices. In this paper, we present a mobile-friendly architecture named \textbf{To}ken \textbf{P}yramid Vision Trans\textbf{former} (\textbf{TopFormer}). The proposed \textbf{TopFormer} takes Tokens from various scales as input to produce scale-aware semantic features, which are then injected into the corresponding tokens to augment the representation. Experimental results demonstrate that our method significantly outperforms CNN- and ViT-based networks across several semantic segmentation datasets and achieves a good trade-off between accuracy and latency. On the ADE20K dataset, TopFormer achieves 5\% higher accuracy in mIoU than MobileNetV3 with lower latency on an ARM-based mobile device. Furthermore, the tiny version of TopFormer achieves real-time inference on an ARM-based mobile device with competitive results. The code and models are available at: https://github.com/hustvl/TopFormer
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract
 Colab
Colab


 ADE20K
ADE20K
 PASCAL Context
PASCAL Context
