TOOLVERIFIER: Generalization to New Tools via Self-Verification
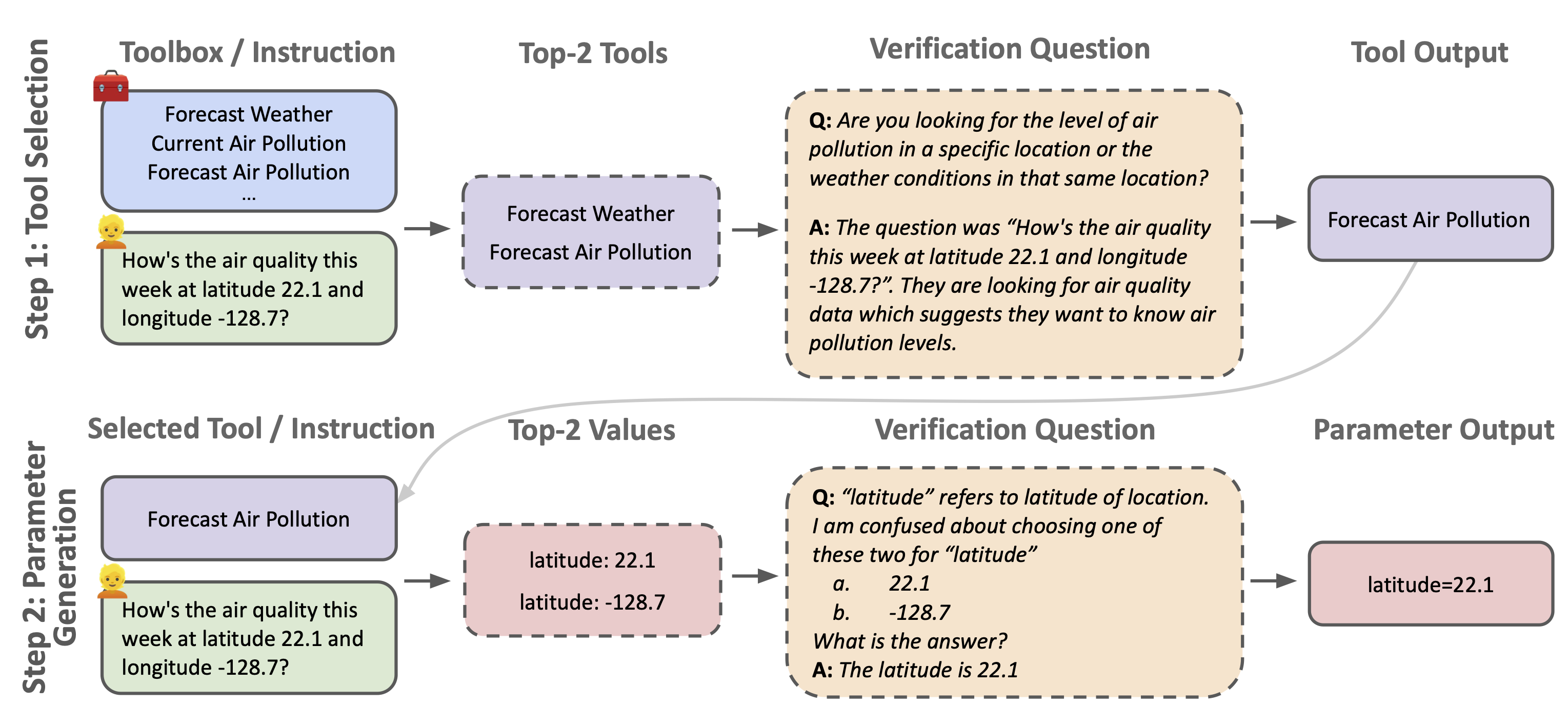
Teaching language models to use tools is an important milestone towards building general assistants, but remains an open problem. While there has been significant progress on learning to use specific tools via fine-tuning, language models still struggle with learning how to robustly use new tools from only a few demonstrations. In this work we introduce a self-verification method which distinguishes between close candidates by self-asking contrastive questions during (1) tool selection; and (2) parameter generation. We construct synthetic, high-quality, self-generated data for this goal using Llama-2 70B, which we intend to release publicly. Extensive experiments on 4 tasks from the ToolBench benchmark, consisting of 17 unseen tools, demonstrate an average improvement of 22% over few-shot baselines, even in scenarios where the distinctions between candidate tools are finely nuanced.
PDF Abstract ToolBench
ToolBench
