To Tune or Not To Tune? How About the Best of Both Worlds?
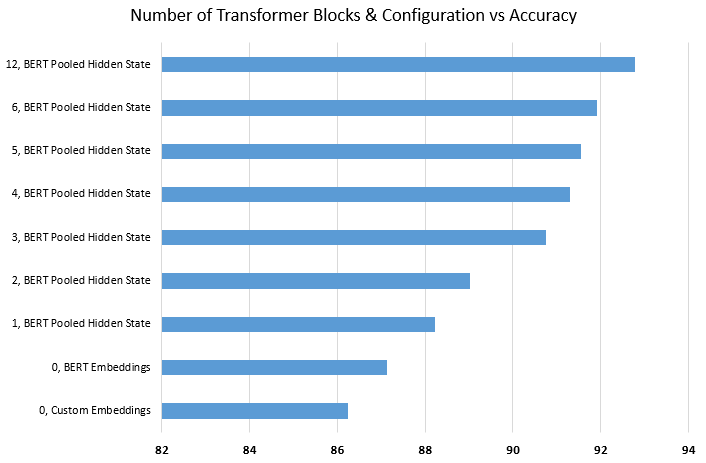
The introduction of pre-trained language models has revolutionized natural language research communities. However, researchers still know relatively little regarding their theoretical and empirical properties. In this regard, Peters et al. perform several experiments which demonstrate that it is better to adapt BERT with a light-weight task-specific head, rather than building a complex one on top of the pre-trained language model, and freeze the parameters in the said language model. However, there is another option to adopt. In this paper, we propose a new adaptation method which we first train the task model with the BERT parameters frozen and then fine-tune the entire model together. Our experimental results show that our model adaptation method can achieve 4.7% accuracy improvement in semantic similarity task, 0.99% accuracy improvement in sequence labeling task and 0.72% accuracy improvement in the text classification task.
PDF Abstract




 GLUE
GLUE
 SQuAD
SQuAD
 CoQA
CoQA
